

Mise à jour de maintenance : sortie de SPIP 4.2.12
Cette nouvelle version apporte quelques améliorations et corrections de bugs.
#spip

SPIP un jour, SPIP toujours ... Une part de manuel, une part de totomatique sur ce compte de short-blogging.
Mise à jour de maintenance : sortie de SPIP 4.2.12
Cette nouvelle version apporte quelques améliorations et corrections de bugs.
#spip

Liste des 10 principaux user-agents dans les 1000 dernières lignes logs au moment de l’énième surcharge du jour : aucun humain
369 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; *GoogleOther* )
246 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; *ClaudeBot* /1.0; +claudebot@anthropic.com)
92 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; *Googlebot* /2.1; +http://www.google.com/bot.html)
76 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 ( *Amazonbot* /0.1; +https://developer.amazon.com/support/amazonbot)
47 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; *GPTBot* /1.0; +https://openai.com/gptbot)
35 SPIP-3.2.19 (https://www.spip.net)
20 Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; *Bytespider* ; spider-feedback@bytedance.com)
19 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; *bingbot* /2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36
15 Mozilla/5.0 (compatible; *AhrefsBot* /7.0; +http://ahrefs.com/robot/)
13 Mozilla/5.0 (compatible; *DataForSeoBot* /1.0; +https://dataforseo.com/dataforseo-bot)J’ai vérifié en allant voir les 10 suivantes. Pareil. Enfin. Mon user-agent caractéristique fini par apparaître à la 19ème ligne.

@seenthis : l’un d’entre vous pourrait-il vérifier pourquoi le système de rejet par 503 des bots en fonction du load ne fonctionne pas ?
Toujours le même classement deux heures après. Ils sont tous en train de récupérer l’intégralité de SeenThis.
359 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
104 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)
100 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; GoogleOther)
53 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
52 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot)
50 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
36 SPIP-3.2.19 (https://www.spip.net)
25 Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; spider-feedback@bytedance.com)
23 Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)
23 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36
Des bots qui récupèrent l’intégralité de Seenthis ...



Vous pouvez expliquer pour les mal comprenant‧es comme moi par exemple ? Merci @biggrizzly @sombre
Ce matin, 8h06.
208 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
194 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; GoogleOther)
52 facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
43 Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; spider-feedback@bytedance.com)
43 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36
42 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)
42 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
38 Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)
35 Sogou Pic Spider/3.0(+http://www.sogou.com/docs/help/webmasters.htm#07)
34 Mozilla/5.0 (compatible; DataForSeoBot/1.0; +https://dataforseo.com/dataforseo-bot)Explications :
– Chaque visiteur utilise un logiciel qui télécharge les pages et les images des pages qu’il visite.
– Chacune des ressources téléchargées génère une ligne de journal dans un fichier dit de « log ».
– Le logiciel, à chaque téléchargement, transmet une chaîne de caractère que l’on nomme « user agent ». C’est le nom du logiciel utilisé, y compris des informations sur le système d’exploitation, et pleins d’autres choses potentiellement.
– Les 10 lignes que je présente sont issues des 1000 dernières lignes de journal regroupées sur le « user agent », avec un décompte du nombre d’occurrences de chacun.
Dans ce dernier export, on constate que les 10 premiers « user agent » représentent 73,1% de l’activité. Et que ceux-ci sont à 100% des robots.

@biggrizzly : Est-ce que ces activités « supra normales » induisent qu’on ait souvent des erreurs « 502 bad gateway » lors d’une tentative de connection ? Moi, pas plus tard qu’hier soir (et de plus en plus fréquemment ces dernières semaines).
@mfmb : je n’ai pas l’expertise de Big Grizzly dans le domaine du web. Mais quand j’apprends que des bots (machines plus ou moins autonomes car automatisées) se mettent à aspirer les données d’une plateforme comme Seenthis, je me pose la question : mais où vont les octets ? Et quelle la nature de l’interface fauteuil-clavier (le gugusse qui est aux manettes) qui se permet de faire ça.
#surveillance (?)
(spoiler : yes)
L’humain soucieux d’éduquer sa progéniture lui donne accès aux livres et aux écoles. Les capitalistes, soucieux de remplacer l’humain, donnent accès à leurs robots aux contenus des réseaux sociaux. Leurs robots pompent tous les échanges humains (écrits, dessins, vidéos) dans l’espoir de créer une intelligence artificielle plus performante que celle du capitaliste voisin, pour enfin pouvoir se passer des humains.
Pomper l’intégralité de SeenThis, ça brûle des ressources, oui, on ferait mieux de leur transmettre directement la base de données... Ils ont de leur côté décidé qu’ils avaient des moyens illimités. Ils construisent des datacenters uniquement pour ce besoin là. C’est consternant d’inutilité. Mais il en ressortira quelque chose, assurément. Avec ou sans nous.

La capture capitaliste du travail gratuit se veut illimitée.
J’omets de répondre à ta question, désolé. Oui, ces erreurs récurrentes, les difficultés à publier ou à répondre, c’est à cause des bots.
Mais comme je l’indique dans une de mes réponses, je ne comprends pas pourquoi les bots ne sont pas refusés (erreur 503), quand la charge de la machine est élevée. J’ai l’impression que lors de la dernière mise à jour, la fonctionnalité a été désactivée, ou quelque chose du genre, et c’est pour cela qu’il serait bon qu’un spécialiste aille regarder, s-il-vous-plait-merci-d-avance.

Je viens de passer une journée a les virer d’un forum. Mardi c’était devenu infernal.
Pour certains c’est assez simple, ils respectent le robots.txt. openai et je ne sais plus quel autre donnent leurs adresse avec le masque cidr qui va bien. Je ne suis pas admin de la machine (donc pas moyen de configurer le pare-feu) mais avec une section <Limit> dans un fichier .htaccess ça marche.
Reste les plus agressifs : bytedance, amazon et quelques autres. J’ai pas la plage IP de ceux la.
Certains t’expliquent sans rire qu’ils relisent le robot.txt tous les 10 jours ! J’ai ajouté des règles de réécriture qui leur balance des erreurs 403. En 24h tout est redevenu normal.
J’en cause plus généralement aussi ici :
▻https://seenthis.net/messages/1051005
9h43, 100% de robots dans les 840 dernières lignes du journal.
458 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; GoogleOther)
176 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.94 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
33 facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
28 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)
28 Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; spider-feedback@bytedance.com)
27 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36
24 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
21 Mozilla/5.0 (compatible; DataForSeoBot/1.0; +https://dataforseo.com/dataforseo-bot)
20 Sogou Pic Spider/3.0(+http://www.sogou.com/docs/help/webmasters.htm#07)
18 Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)
Mince je n’avais pas vu tes pings @biggrizzly (normal le ping vers @seenthis n’est plus relayé sur discourse), n’hésite pas à me pinger en direct :)
Si les bots ne sont pas bloqués, il y a deux pistes : soit leur user agent n’est pas dans la liste déclaré par l’écran de sécu de SPIP cf ▻https://git.spip.net/spip-contrib-outils/securite/-/blob/master/ecran_securite.php?ref_type=heads#L44 ou alors PHP n’a pas accès à sys_getloadavg cf ▻https://git.spip.net/spip-contrib-outils/securite/-/blob/master/ecran_securite.php?ref_type=heads#L740

Merci pour les pistes @b_b. Depuis, donc, un certain temps, ça génère du 429, au lieu de 503. Je n’avais pas vu. Du coup, je constate que ça vire du monde, déjà. Et je constate, donc, que ça n’exclut pas beaucoup de bot, du fait de la règle qui est très peu excluante. La règle actuelle ne suffit pas. Je vais modifier la règle, en la rendant très excluante, et on va voir si ça va mieux. Merci encore.
@biggrizzly la règle est retreinte à cause du fichier ecran_secrite_config.php qui défini une règle perso, alors que celle de SPIP est bien plus large. On en cause en direct sur IRC ou autre si tu veux.
Depuis que j’ai compris que ça déclenchait des 429 plutôt que des 503, j’ai pu adapter mes scripts (basiques) d’analyse des logs, et je vois désormais qu’il y a bien un effet de la part de ce système.
Comme tu dois pouvoir le voir, j’ai ajouté des filtres très génériques. Apparemment, le load ne monte plus au dessus de 2, pour le moment. A suivre. Et j’espère qu’il n’y a pas de user-agent légitime qui contient « bot »... :-))
@biggrizzly on est pas les seules personnes à subir claudebot cf ▻https://mastodon.social/@nixCraft/112344003877391227
Et je commence aussi à observer des rush de ce bot chez infini.
On a de la chance que ces bots s’identifient avec un user agent, et des plages ip. Ils ne sont pas totalement malveillant non plus.
Puisqu’on en parle, des bots pas sympa, en voilà un gratiné. Si on se demande pourquoi pendant 5 minutes SeenThis était difficile d’accès, on peut demander des comptes au user-agent suivant : Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36
Dans les 1000 dernières lignes de log, il communiquait avec SeenThis depuis 4 adresses IP :
87 183.192.118.124
30 183.192.118.126
18 183.192.118.18
137 183.192.118.26Nous avons donc des bots qui tentent de se faire passer pour autre chose qu’un bot.

De notre côté on s’est fait aussi pourrir par un ClaudeBot…
Y en a un (je sais pas si c’est le même) qui change son UserAgent à chaque hit aussi…

Exclusif : C’est désormais une certitude, le chômage tue - POLITIS
►https://www.politis.fr/articles/2024/04/assurance-chomage-etude-inserm-cest-desormais-une-certitude-le-chomage-tue
Surtout, plusieurs études internationales établissent le lien entre la qualité de la protection sociale et la plus faible surmortalité liée au chômage. Autrement dit, plus l’assurance-chômage est protectrice, plus elle permet d’atténuer la violence du chômage et donc de réduire l’augmentation des facteurs de risque cardiovasculaire. Une étude comparée entre les États-Unis et l’Allemagne est très claire sur ce point. Alors que l’Allemagne présente une surmortalité liée au chômage bien moindre qu’outre-Atlantique, les chercheurs concluent : « [Ce résultat] confirme l’hypothèse selon laquelle l’environnement institutionnel, y compris des niveaux plus élevés de chômage et de protection de l’emploi, tempère la relation chômage-mortalité. »
Diminuer la protection sociale va augmenter la surmortalité.
P. Meneton
En France, du fait d’acquis sociaux importants et d’un modèle social plus protecteur, la surmortalité liée au chômage est bien inférieure à celle observée aux États-Unis, par exemple. Dans le pays du libéralisme, celle-ci s’élève à 140 %, selon la même étude ! « On peut donc aisément faire l’hypothèse que diminuer cette protection sociale va augmenter la surmortalité », commente Pierre Meneton, qui rappelle que les résultats trouvés sont « a minima ».
Encore un titre trompeur. Ce n’est pas le chômage qui tue mais le manque d’argent.

Eh non, ce qui tue c’est le manque de moyens dignes pour subvenir à ses besoins. L’argent n’est qu’une (sale) manière dans l’organisation de la production actuelle. Mais avoir un logement décent, de la nourriture suffisante et de qualité, la santé, et participer à la vie en commun (à produire ces subsistances et à la vie politique), ce n’est pas le manque d’argent le problème.
Oui, oui, faisons comme si le capitalisme et son équivalent général n’existait pas et tout ira mieux.

Ah tiens, encore les vieux gauchos qui n’ont pas besoin de recevoir de leçon sur internet (leur science est infuse et leur connaissance indépassable) et qui ont mis un WP à la place de SPIP
hé ben oui, je m’y habitue pas, pourtant qu’est-ce que j’en vois passer, et puis surtout avec tout plein d’arguments sans savoir du tout de quoi iels parlent, pire que des gamins, extraordinaire. C’est un peu comme les cibles commerciales privilégiée d’apple : celleux qui ne connaissent rien à la techeunique et rechignent jusqu’à ce qu’un jour ils lâchent le pactole pour un téléphonesniffer dernier cri et qu’ils se lancent de façon acharnée sur les réseaux qui puent, ravis de ne plus dormir la nuit, plongés sur leur truc même durant les repas.
Comment ça j’ai mangé des cactus ?
C’est justement parce qu’il y a cette marchandise-équivalent-général que ça ne va pas et que ça tue. Donc c’est pas son manque le problème mais son existence : tant qu’il y aura de l’argent, il n’y en aura pas pour tout le monde, jamais.
Je n’ai jamais oublié la leçon que nous avons apprise aux portes des usines, lorsque nous arrivions avec nos tracts prétentieux, invitant les travailleurs à rejoindre la lutte anticapitaliste. La réponse, toujours la même, venait des mains qui acceptaient nos chiffons de papier. Ils riaient et disaient : « Qu’est-ce que c’est ? De l’argent ? ». Ils étaient de cette « race païenne brutale », en effet. Ce n’était pas le mot d’ordre bourgeois « enrichissez-vous ! », c’était le mot salaire, présenté comme une réponse objectivement antagoniste au mot profit. L’Opéraïsme a retravaillé la brillante phrase de Marx – le prolétariat atteignant sa propre émancipation libérera l’humanité entière – pour lire : la classe ouvrière [3], en suivant ses propres intérêts partiels, crée une crise générale au sein des rapports sociaux capitalistes.
▻https://lesmondesdutravail.net/notre-operaisme-mario-tronti
▻https://www.revolutionpermanente.fr/La-precarite-tue-une-etude-de-l-Inserm-pointe-la-surmortalite-l
Sans surprise, donc, les personnes vivant une situation précaire et d’inemploi ont plus de risques de vivre des épisodes dépressifs qu’un actif. De plus, plus le chômage est de longue durée, plus les risques s’accroissent. Ces résultats mettent en lumière l’impact profond du chômage sur la santé mentale et physique des individus qui constituent « l’armée de réserve du capital ».
Les résultats de cette étude tombe mal alors que le gouvernement cherche à faire passer les personnes en situation d’inemploi pour des « profiteurs », pour justifier ses offensives contre l’assurance-chômage, et contraindre les allocataires de l’assurance chômage à accepter des emplois précaires et mal rémunérés – ou à rejoindre les rangs des allocataires du RSA, lui aussi « réformé ».
Travail forcé ou travail forcé : dès qu’ils sentent que le rapport de force peut leur devenir défavorable, ils te démontrent que le « marché du travail » n’existe pas, il n’y a que la guerre des classes et les bourgeois, ils ont la main sur les lois pour nous faire plier à leur cupidité.

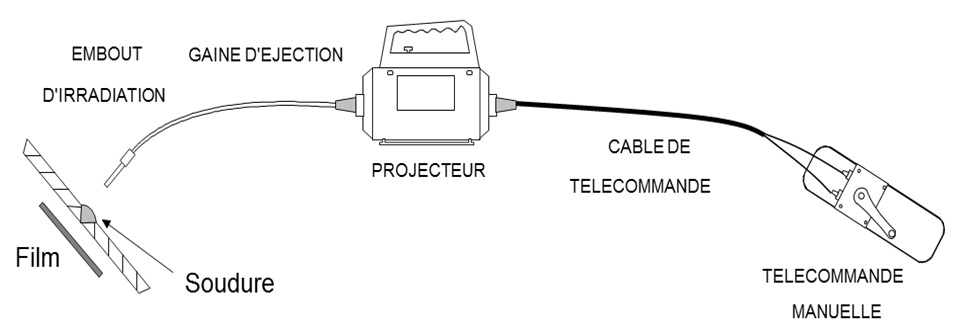
23/04/2024 - Décryptage sur l’incident à Colmar avec une source radioactive d’iridium 192 - CRIIRAD
▻https://www.criirad.org/23-04-2024-decryptage-sur-lincident-a-colmar-avec-une-source-radioactive-di
À Colmar, le 10 avril 2024, en fin d’après-midi, suite à un incident avec une source radioactive d’iridium-192 utilisée sur le site de l’entreprise ADF pour des opérations de gammagraphie, un périmètre de sécurité a dû être mis en place.
Ce type de source de forte activité émet en effet de puissantes radiations gamma capables de traverser le métal et les murs et de se déplacer dans l’air sur des dizaines de mètres.
La récupération de ce type de source de forte radioactivité est une opération très délicate.
En 2010, sur le site de la fonderie Feurs métal, dans la Loire, une source de 1,25 TBq de cobalt 60 est restée bloquée. La tentative de récupération, par le service intervention de l’IRSN, au moyen d’un dispositif de cisaillage robotisé, avait entraîné la contamination de 6 personnes et de 3 000 m2 de bâtiments. Quatorze ans plus tard, l’assainissement du site de Feurs n’est pas terminé.
CSS :has() Interactive Guide
▻https://ishadeed.com/article/css-has-guide
On peut faire des trucs sympas avec :has(), exemples :
With CSS :has(), we can replicate the logical operators like ”&&” and ”||“
/* OR */
.shelf:has(.bookPurple, .bookYellow) {
outline: dashed 2px deeppink;
}
/* AND */
.shelf:has(.bookPurple):has(.bookYellow) {
outline: dashed 2px deeppink;
} In this example, I want to show an additional visual clue if the page has an alert.
.main:has(.alert) .header {
box-shadow:
inset 0 2px 0 0 red,
0 3px 10px 0 rgba(#000, 0.1);
background-color: #fff4f4;
}Et plein d’autres trucs comme “Quantity queries with CSS :has” , “We can select an element if it’s followed by another.”, “For example, if the user selects “other”, we want to show input to let them fill in more info.” qui pourrait être utile à saisies de #SPIP et son afficher_si, etc.

Alors j’aime beucoup :has. Mais j’y vais tout de même mollo : on se retrouve rapidement avec des CSS avec une structure imbitable. Surtout si en plus on utilise des CSS imbriqués (puisque la logique du :has contredit la stricte lecture descendante des CSS imbriqués).

Pour l’aspect rapidement illisible, ça vient aussi du fait qu’on utilise :has pour faire des choses qu’on ne peut pas faire autrement. Et par exemple sur un truc que je fais en ce moment, je me retrouve à faire des choses comme ceci :
#timeline:not(:has(li:nth-child(6))) li:nth-child(1)::before { … }:has, j’essaie de rester plus simple.
Depuis quelques mois (en gros vers l’automne 2023), j’ai régulièrement des clients qui me signalent que leur site se met à ramer, ou à déconner, et on ne trouve pas trace de piratage (SPIP 4.2, ouf).
Mais en regardant les logs, je trouve des IP, généralement géolocalisées à Hong-Kong, qui balancent des requêtes à un rythme effréné (là, je viens d’avoir deux IP qui, depuis des jours, balancent 10 requêtes par seconde sur les pages Web d’un même site).
Quelqu’un a une idée de ce que c’est que ces trucs ? Ça m’a l’air d’aspirer des pages légitimes, je ne trouve pas des requêtes « bizarres », genre qui tapent des adresse connues de trous de Wordpress.
(Perso je me demande si c’est des moissonneurs mal branlés destinés à alimenter des LLM.)
(je suis de cet avis, je constate les mêmes comportements, pas que sur des sites SPIP ; SeenThis depuis plusieurs semaines se prend ces pics de charge d’ailleurs, qui explique parfois la difficulté à poster)
Ma théorie-purement-théorique : à une époque des gens se mettaient à fabriquer des collections (assez merdiques, pas qualifiées, mais pas chères) d’adresses emails, qu’ils revendaient parce que tout le monde cherchait des listes de victimes à spammer ; je suspecte qu’aujourd’hui, des gens se croient malin en lançant des aspirations massives du Web, dans l’espoir de revendre des fichiers de contenus pour alimenter des modèles de langage. (Parce qu’une fois que tout le monde a aspiré les livres de fondation Gutenberg, on s’est bien rendus compte que ça faisait des IA qui te causaient comme au XIXe siècle.)
Après, s’ils passent sur Seenthis, ça va faire des IA anarcho-syndicalo-marxo-léninistes.
Un exemple tout récent. Le serveur était non-visité depuis des années. Il s’agit d’un truc public, contenant des wikis et un bugtracker. Plein de contenu qui a été vivant à une époque. Depuis une semaine, le serveur ne cesse de faire le yoyo. Surcharge, surcharge, surcharge.
A noter que le même graph pour SeenThis ne montre pas d’évolution particulière depuis un an...
Un load de 30 ou 40, cela signifie que 30 à 40 processus fonctionnent au moins une minute en continu.
Des load en pointe à 80 pour SeenThis, c’est énorme... mais ce n’est pas forcément anormal étant donné le contenu.
L’Association des Maires Ruraux de France re lance son Campagnol.fr : un service complet permettant de disposer d’un site internet communal pour pas trop cher.
Bonne idée après tout.
Un petit coup d’œil sur le code source des sites présentés permet de voir que c’est tout en wordpress :/ et bourré de liens tiers. Ça me fait marrer quand même, ça suit bien la politique habituelle de scier la branche du logiciel français Libre et c’est en plus sur la couche du framework bootstrap. Un truc mastoc qui est évité désormais en développement web est peu performant.
<link rel='dns-prefetch' href='//maxcdn.bootstrapcdn.com' />
<link rel='dns-prefetch' href='//fonts.googleapis.com' />
<link href='https://fonts.gstatic.com' crossorigin rel='preconnect' />
Tu ne parlerais pas plutôt d’un logiciel francophone ? ^^
Ben non, je dis bien français malheureusement, parce que c’est typique français depuis longtemps. Je pense à des inventions comme le cinéma, l’électricité, le format vidéo, et même les ruches.
Bref, des inventrices et des inventeurs, voire des pratiques (pour les ruches) avec encore un peu de créativité, qui tiennent la route mais supplantés systématiquement par des politiques commerciales à court terme.
Sinon oui bien sûr, on pense à SPIP :)

Plusieurs failles de sécurité ont été repérées dans les versions 1.9.2, 2.0 et 2.1 de SPIP.
La faille concernant la version 1.9.2 est majeure (injection sql) et si vous avez une version 1.9.2 de SPIP, nous conseillons vivement de faire la mise à jour en 1.9.2.k.
Concernant les versions 2.0 et 2.1, si l’impact sur un site est moins important (full path disclosure), nous conseillons toutefois de mettre à jour en 2.0.16 et 2.1.11.
Dans tous les cas vous avez toujours la possibilité de protéger rapidement votre site (en attendant sa mise à jour complète) en téléchargeant la version 1.0.5 (26 juillet 2011) de l’écran de sécurité, et en la déposant dans votre répertoire config/ (cf. ►http://www.spip.net/fr_article4200.html).
N’hésitez pas à utiliser les différents moyens mis à disposition de la communauté (►http://boussole.spip.org) pour obtenir de l’aide lors de cette mise à jour ; en particulier :
liste spip-user ►http://listes.rezo.net/mailman/list...
forum ►http://forum.spip.org
IRC ►http://spip.net/irc
Avertissement :
Noter qu’à la sortie de la version 3.0, le support de la branche 1.9.2 sera définitivement abandonné.
SPIP 1.9.2k, 2.0.16, 2.1.11 et 3.0.0-beta disponibles - SPIP-Contrib
►http://www.spip-contrib.net/SPIP-1-9-2k-2-0-16-2-1-11-et-3-0-0-beta-disponibles
Plugin #SPIP : ez-css. Le framework css facile et efficace pour afficher ses sites à l’identique sur tous les navigateurs. - SPIP-Contrib
►http://contrib.spip.net/ez-css-le-framework-css-facile-et-efficace
Musée des impressionnismes Giverny. Très joli site porté par #SPIP

Pensez sauvage vous propose des graines cousues main, faites dans le respect de l’environnement et du vivant. Des graines de ferme certifiées biologiques, reproductibles et qui sont produites artisanalement.
Des semis aux sachets, tout est fabriqué à la main et sur la ferme.
►https://pensezsauvage.org
#graines #catalogue #achat #graines #semences #tomates #fleurs #légumes

Super site SPIP, magnifiques variétés de plantes, et il fallait trouver cette bande sonore rafraîchissante : ▻https://pensezsauvage.org/melons/graines_de_melon_kajari (le mp3 sous les vignettes)...
\o/
(J’arrive pas à poster de message sur forum.spip.net.)
J’ai un gros souci qui arrive de plus en plus fréquemment : impossible de modifier une table mySQL. Et dans les deux cas où ça m’est arrivé, ce sont des serveurs sur lesquels je n’ai pas la main sur la config.
Je me cogne le fameux message :
Invalid default value for 'date'mais dans les deux cas je ne trouve pas de solution que je puisse appliquer.
(J’arrive pas à poster de message sur forum.spip.net.)
C’est normal, il est fermé depuis qu’on utilise ►https://discuter.spip.net :)

Tu aurais plus de chance sur ►https://discuter.spip.net :)
(forum.spip.net a été fermé il y a un moment et n’est conservé que pour l’historique)
Ah zut, oui.
Bon, mais pas mieux, je ne trouve rien qui règle mon problème :
▻https://discuter.spip.net/t/spip-dev-mysql-5-7-et-suite-des-problemes-de-date/17579/3
(Ma solution pour l’instant : passer en SQLite.)
SRWieZ/thumbhash : Thumbhash implementation in #PHP
▻https://github.com/SRWieZ/thumbhash
▻https://evanw.github.io/thumbhash
Thumbhash PHP is a PHP library for generating unique, human-readable identifiers from #image files. It is inspired by Evan Wallace’s Thumbhash algorithm and provides a PHP implementation of the algorithm.
Thumbhash is a very compact representation of a #placeholder for an image. Store it inline with your data and show it while the real image is loading for a smoother #loading experience. It’s similar to #BlurHash but with some advantages
Merci ! C’est cool pour protéger ses images qu’on ne veut partager qu’avec les visiteurs connectés et pour plein d’autres utilisations.
Est-ce qu’on aura un filtre (facile) ou plugin #SPIP ?!?
Est-ce qu’on aura un filtre (facile) ou plugin #SPIP ?!?
huhu, ça se pourrait si quelqu’un le faisait, perso c’est pas dans ma todo :)
Mise à jour de maintenance : sortie de SPIP 4.2.10
Cette nouvelle version apporte quelques améliorations et corrections de bugs.
#spip
L’occasion de découvrir qu’apparemment, Jean-Pierre Chevènement n’est pas mort.
L’occasion de découvrir qu’apparemment @seenthis non plus ►https://github.com/seenthis/seenthis_squelettes/issues/292
@b_b en train de mettre à jour Seenthis en SPIP 4.1, wow ! Un truc de loco in the brain…

Deux jours de travail plus tard, j’ai un #seenthis qui fonctionne en PHP 8.1 sans afficher le moindre warning ou deprecated (et c’était ça le plus gros du chantier au final). Prochain temps libre, j’attaque la compat SPIP 4.2 et PHP 8.2...
@seenthis : J’ai créé un ticket hébergement sur le github de SeenThis, ticket 29.
J’ai des questions. Je propose qu’on en discute là bas.
Merci pour vos retours.


@b_b @arno @rastapopoulos @les_autres, j’ai besoin d’aide pour prendre des décisions SVP :-) Aide sur SPIP et le fonctionnement de son répertoire tmp, aide sur Sphinx et son déploiement désormais, etc. Ce n’est pas grand chose, je pourrais improviser, mais bon. Si je pouvais éviter de tâtonner :-)
Merci pour le ticket, j’y réponds dès que j’ai un moment !
Hello,
J’ai créé un autre ticket, ce jour :
▻https://github.com/seenthis/hebergement/issues/30
Et un autre :
▻https://github.com/seenthis/seenthis_squelettes/issues/295
Oui, y-a un ticket squelette, oui, je suis allé lire le code PHP.
Les initiés, pouvez-vous me donner vos avis ?
En gros :
1) seenthis fonctionne avec un webcron, qui s’exécute quand qq’un consulte, cette consultation peut se retrouver très lente en conséquence, plusieurs secondes. Est-il possible de décider de déporter ce webcron dans un vrai cron ?
2) J’étudie, sur le serveur de future prod, les lenteurs mariadb (slow log), et la première lenteur, c’est la construction du fil personnel, qui construit des requêtes à coup de « sql_in ». Avec nos vieux comptes, cela construit des in avec plusieurs centaines d’ID. La seconde lenteur, c’est l’update sur spip_syndic, et là, j’ai l’impression qu’on tombe sur une vraie difficulté, grosse table avec des millions d’enregistrements, et plusieurs index complexes.
Pouvez-vous me faire des retours sur ces sujets SVP ?
Pas accès à la base de données, alors je sais pas trop pour spip_syndic.
À priori, c’est utilisé pour les comptes alimentés par des flux RSS, je ne vois pas pour quoi d’autre ce serait utilisé. Et en plus c’est censé de déconnecter automatiquement au bout d’un certain temps, pour éviter d’avoir des zombies qu’on garde pendant des années.
Du coup, c’est spip_syndic, ou spip_syndic_articles qui a des millions d’enregistrements ?
Si c’est spip_syndic_articles qui est monstrueux, est-ce qu’on ne pourrait pas effacer les anciennes entrées au bout d’un moment, vu que de toute façon sur Seenthis on transforme ce qu’on récupère via les flux RSS en billets Seenthis « normaux » ?
Tu sais que je peux te créer un accès ssh ? :-)
1) le cron est asynchrone, il ne devrait pas avoir d’impact pour les visiteurs du site cf ▻https://programmer.spip.net/Fonctionnement-du-cron ; on doit pouvoir le désactiver et le brancher sur un cron système, à discuter dans le ticket :)
2) ça me rappelle ce ticket ▻https://github.com/seenthis/seenthis_squelettes/issues/159
Concernant la table spip_syndic si ma lecture du code est bonne, elle contient les urls des sites référencés dans les posts. Mais bon, je ne fais que maintenir, je n’ai pas participé à la création du bouzin :p
Ça me contrarie ce que tu me dis sur le cron asynchrone. J’ai des lenteurs qd il se déclenche, apparemment, mais il se peut que ce soit pour une autre raison, donc, que la page s’affiche lentement...
J’ai lu le ticket que tu as indiqué. Les requêtes en l’état sont contre performantes, même si elles fonctionnent bien. Elles pourraient fonctionner mieux. Ceci dit, s’il y avait 10 ou 100 fois plus de trafic, on serait face à de grosses difficultés pour la montée en charge.
Je mets en pause mon profiling pour repasser sur l’installation de manticore. Faut que j’avance sur le nouveau serveur.
N’empêche que je n’ai pas encore réussi à identifier le coupable des lenteurs à la publication. C’est frustrant.

Tables in Markdown | Codeberg Documentation
▻https://docs.codeberg.org/markdown/tables-in-markdown
documentation de la syntaxe MarkDown pour les tables/tableaux
NB :
– à priori fourni en tant qu’extension par la version "GitHub Flavored" MarkDown (GFM) : cf la définition/spécification sur ▻https://github.github.com/gfm/#tables-extension-
– ne semble pas supporté par la version "Commonmark" MarkDown (cf son absence dans la définition sur ▻https://spec.commonmark.org )
– ne propose aucune option de fusion de cellules (contrairement à SPIP) : seul MultiMarkdown semble le proposer : cf ►https://github.com/fletcher/MultiMarkdown/wiki/MultiMarkdown-Syntax-Guide
#markdown #MD #GFM #GitHub_Flavored #Commonmark #syntaxe #tableau #table
Bonjour, les SPIPeur,
Petite question sur la possibilité d’avoir un outil pour automatiser l’envoi d’une lettre d’info avec les derniers articles publiés sur un site #SPIP. Ça existe ?
La question concerne le site de notre syndicat. Un truc une fois par mois qui se met en page tout seul et où on peut (ou pas) ajouter quelques mots d’édito serait bienvenu.
Merci.
Perso c’est le genre de chose que je fais avec un format d’article spécifique, avec du HTML le plus rustique possible (avec des <table> dans des <table>, beuark), et un raccourci du genre <lettre125> pour insérer des liens maquettés vers les articles sélectionnés).
Et l’envoi à la mano en recopiant le code source de la page dans un outil de newsletter.
Par exemple la semaine hebdomadaire d’Orient XXI :
▻https://orientxxi.info/outils/la-lettre-d-information/archives/la-lettre,7061

@monolecte @arno aime bien réinventer la roue :p, mais sinon tu as le plugin… Newsletters (+ Mailsubscribers pour gérer les inscrits en interne + Mailshot pour gérer les envois en masse).
Tu as quelques modèles fournis pour t’inspirer mais tu peux soit les surcharger pour les personnaliser soit créer ton propre modèle. Chaque lettre à un titre et un texte entier comme un article donc tu peux aussi écrire un truc dédié dans chaque en plus du squelette qui te sortirait des trucs automatiques. T’as aussi un système de variables possibles à mettre dans ton texte pour personnaliser un peu genre « Bonjour @nom@ » (cf la doc).
Ensuite ça te l’envoie en masse avec différents services reconnus (l’envoi en masse doit absolument se faire par un service dédié pour pas être reconnu comme spam), genre sparkpost, mailjet, etc.
C’est très simple et très bien documenté.
►https://contrib.spip.net/newsletters
@monolecte tu as par defaut dans SPIP depuis perpette Configuration-> Interactivité -> Notifications, Suivi de l’activité éditoriale > Envoi de mails automatique > Annonce des nouveautés tous les X jours.
Tu peux changer le squelette de la lettre mais basiquement ça le fait sans rien ajouter.
Après le souci principal consiste à la livraison de tes mails pour qu’ils n’arrivent pas en spams ou pas du tout. Ça dépend aussi combien de destinataires il y a. A minima, il faut le plugin facteur configuré en SMTP et un domaine avec la zone DNS qui contient bien DKIM DMARC et SPF correct. Un outil de test derrière comme mail-tester, avec des tests depuis facteur évidemment pour obtenir le meilleur envoi.
++
Pour la délivrabilité, Touti a donné les mots clefs. Je peux t’assister ds la mise en oeuvre ou le diagnostic si besoin.
Je partage mon outil de validation de prédilection, créé par une connaissance : ►https://scanmy.email
Merci à tou·te·s ! 💝
Je savais que je pouvais compter sur vous.
Cela dit, je ne suis pas le webmestre du syndicat, mais je fais remonter.
(j’ai déjà assez de trucs sur le feu).
Ha super, merci pour le lien @biggrizzly je vais peut-être en faire un post à part pour l’avoir au chaud :p
Oui, merci @biggrizzly : mes deux mails principaux sont bien…
Vous avez de la chance qu’il fonctionne pour vous. Moi, là, depuis hier, je ne parviens pas à obtenir de résultat !
Pour de rire, j’ai attendu, ça monte à plusieurs milliers de %.
Mais oui, il a déjà plus de 3 ans : i7-1165G7
@biggrizzly bonne idée d’avoir une alternative mais ça me ressort des erreurs qui n’existent pas.
Genre obligation d’un p=xxx dans le DKIM alors qu’il le liste
ou bien un spam sur ▻https://check.spamhaus.org qui confirme ne pas avoir l’IP listée, oups :/
Il me dit qu’il doit y avoir une anomalie dans son usage de la liste Zen, car 1), il va supprimer la mention « CBL », qui est obsolète, et 2) il va vérifier qu’il interroge convenablement la liste.
Mise à jour de maintenance : sortie de SPIP 4.2.9
Cette nouvelle version apporte quelques améliorations et corrections de bugs.
#spip
Perrier, Vittel, Hépar, Contrex... pourquoi Nestlé a-t-il désinfecté ses eaux minérales avec des traitements interdits ? - midilibre.fr
▻https://www.midilibre.fr/2024/01/30/perrier-vittel-hepar-contrex-pourquoi-nestle-a-t-il-desinfecte-ses-eaux-mi
Sophie Dubois, directrice de Nestlé Waters France, a confié tous ses espoirs de croissance pour le site historique de la Source Perrier à Vergèze, dans le Gard à Midi Libre. Désormais, deux puits sur huit produiront une eau de consommation humaine qui ne pourra pas se prévaloir de l’appellation d’eau minérale. « Nous lançons Maison Perrier, une nouvelle gamme d’eaux aromatisées, qui n’auront pas les caractéristiques de l’eau de Perrier mais correspondent à un nouveau segment de consommation en très forte croissance », assure Sophie Dubois.
Conséquences
L’arrêt du recours à ces dispositifs de traitement et de filtration a obligé Nestlé Waters à suspendre l’activité de certains de ses puits dans les Vosges. Cet arrêt qui a conduit à une réduction des volumes de production d’Hépar et de Contrex.
Nestlé et d’autres industriels ont purifié illégalement de l’eau contaminée pour continuer de la vendre
►https://www.radiofrance.fr/franceinter/nestle-et-d-autres-industriels-ont-purifie-illegalement-de-l-eau-contami
Tout commence en décembre 2020, après un signalement de fraudes au sein du groupe Sources Alma, qui produit une trentaine d’eaux en bouteille en France, dont Cristaline, “l’eau préférée des Français”, mais aussi Saint-Yorre, Vichy Célestins ou encore l’eau de Châteldon, une eau “d’exception” qui “se fit connaître à la cour des rois de Versailles pour ses vertus digestives”, selon le site internet de la marque.
Sur la base d’un signalement d’un salarié d’une usine du groupe Alma, la Direction générale de la concurrence, de la consommation et de la répression des fraudes (DGCCRF) ouvre une enquête. Elle découvre que l’entreprise fait subir à ses eaux minérales des traitements non conformes à la réglementation : injection de sulfate de fer et de CO2 industriels, microfiltration inférieure aux seuils autorisés, mais aussi mélanges d’eaux dites “minérales” ou “de source” avec de l’eau… du réseau, celle qui coule au robinet.
Voir aussi : ▻https://seenthis.net/messages/1039099
Mais surtout : pourquoi avoir attendu 3 ans pour informer le public ?
Et comment ça se fait qu’en fait Nestlé continue pépère ses petites affaires et qu’on t’explique que les autorités n’ont l’air de n’avoir que les déclarations de Nestlé sur e retour à la normale ?
On parie combien qu’il ne faudrait pas trop mettre son museau dans les autres embouteilleurs ?
Et que les gus qui achètent ça se tapent régulièrement de l’eau du robinet tout en polluant ?
Et en payant très cher un produit qui n’a aucun intérêt en terme de santé (plus ingestion de micro-particules de plastique) ...
Va falloir passer aux filtres. Oui mais lesquels. Je crois que tu en avais déjà parlé @monolecte.
Vous vous souvenez qu’il y a tout juste 3 mois, le directeur de l’ARS Occitanie conseillait de boire de l’eau du robinet ?
Je demandais alors :
▻https://seenthis.net/messages/1022218#message1022235
Qu’est-ce qu’il différencie une eau minérale d’Occitanie d’une eau du robinet qui provient d’Occitanie ?
Maintenant on a une petite idée.
Pour les filtres, j’utilisais BWT magnésium… qui se trouve à un prix raisonnable.
Mais avec des carafes Brita.
Le truc, c’est que Brita a rajouté des détrompeurs pour niquer les concurrents qui avaient des filtres compatibles. Alors qu’il sont nuls en filtres.
Mais bon en carafe.
Surtout ce genre pour toute l’eau potable : ▻https://www.brita.fr/systemes-de-filtration/carafe-filtrante/flow
▻https://cdn.brita.net/.imaging/opt/w482/h482/1694599791058/dam/jcr:5dd8914a-775b-4dd7-a187-26d3bb383f90/brita-waterfiltertank-flow-1564x1564px-maxtra-pro.webp
Donc, on prend des cartouches magnésium génériques avec détrompeur es croisant les doigts pour que les fabricants ne soient pas des gorets.
Car faire de la merde, c’est devenu un peu la vocation du capitalisme.
Note pour @seenthis : afficher les .webp
@monolecte on a un vieux ticket à ce sujet ici ►https://github.com/seenthis/seenthis_squelettes/issues/13 ça sera possible si un jour seenthis est mis à jour en SPIP 4 :)
@biggrizzly pas les tiennes mais plutôt les miennes :p
Si, si, les miennes aussi... Debian, tt ça... :-))
Eaux en bouteille : des pratiques trompeuses à grande échelle
Pendant des années, des eaux vendues comme « de source » ou « minérales naturelles » ont subi des techniques de purification interdites. Selon une enquête conjointe du « Monde » et de Radio France, un tiers au moins des marques françaises sont concernées, dont celles de Nestlé, qui a reconnu ces pratiques. Informé depuis 2021, le gouvernement a assoupli la réglementation dans la plus grande discrétion.▻https://www.lemonde.fr/planete/article/2024/01/30/eaux-en-bouteille-des-traitements-non-conformes-utilises-a-grande-echelle_62
cartes GIS offline · brunob/expoos d9ebe9a · GitHub
▻https://github.com/brunob/expoos/commit/d9ebe9aa0f69e172e6905fcf322f2846a22862fa
SPIP : adapter le code des cartes GIS pour qu’elles fonctionnent bien en offline
– insertion du JS de GIS par insert_head à l’ancienne pour qu’il soit bien caché
– on ne charge pas le JSON des points depuis le modèle GIS (en ajax donc), mais depuis l’event ready de la carte à l’aide de la méthode parseGeoJson() de l’API JS de GIS (le json étant directement dnas le source de la page il est bien caché)
(merci @b_b !)

TaxiFilmFest - Fiction and truth, taxi legends and reality, in film and reality.
▻http://www.taxifilmfest.de/article2.html
 https://www.taxifilmfest.de/IMG/jpg/taxihalte-europacenter_nacht_cc-by_flickr_extranoise_blurred.jpg
https://www.taxifilmfest.de/IMG/jpg/taxihalte-europacenter_nacht_cc-by_flickr_extranoise_blurred.jpg Visit us during the 17th Berlinale on Potsdamer Straße !
Take part in the TaxiFilmFest Berlin !
Organise your own TaxiFilmFest !
Taxis and film are children of the progress of technology, of dream and reality. That’s why there are taxis in so many films. They are the starting point and turning point of stories. In some films, the taxi takes centre stage.
The TaxiFilmFest shows the human and cultural wealth that our colleagues at the wheel create day after day. All over the world, monopolistic platforms are attacking this culture. Those involved in the TaxiFilmFest are fighting back against material and artistic impoverishment.
The Taxi Film Festival is more than just a film event. Its contributions and workshops open up a view of the world in which we want to live, in which everyone can make a good living from their work. We strengthen the taxi as a place of encounter and culture.
Berlin TaxiFilmFest (in Entwicklung)
►https://www.taxifilmfest.de
Vom 15. bis 25. Februar 2024 findet auf der Potsdamer Straße zwischen Sony-City und Daimler-City das TaxiFilmFest statt. Ab Montag, den 22.1.2024 zur Berlinale Programm-Pressekonferenz werden auch das Konzept und Programm des Berliner TaxiFilmFest veröffentlicht.
Die Versammlungsbehörde hat diesen Ankündigungtext veröffentlicht:
►https://www.berlin.de/polizei/service/versammlungsbehoerde/versammlungen-aufzuege
Das Taxi als Teil des öffentlichen Nahverkehrs (ÖPNV) und der Stadtkultur ist bedroht. Die Leitung der Berlinale positioniert sich im Jahr 2024 bereits zum zweiten Mal gegen das Taxi und bietet dem größten Feind von guter Arbeit, von Taxi- und Filmkultur eine Werbefläche als Hauptsponsor. Dagegen setze ich gemeinsam mit den Unterstützern von Taxi Deutschland, Taxiinnung, Ver.di, dem Arbeitslosenzentrum Evangelischer Kirchenkreise die Kundgebung TaxiFilmFest. Wir wollen mit Filmschaffenden und Publikum der Berlinale ins Gespräch kommen. (vom 15.02. bis 25.02.2024 - täglich)
#Berlin #Taxi #Film #Berlinale #TaxiFilmFest #2024 #SPIP 4.2
Dans mon #plugin #SPIP Insertion avancée d’images :
▻https://plugins.spip.net/medias_responsive_mod.html
il y a une fonction que j’utilise beaucoup : include_svg.
Elle permet d’inclure directement dans le HTML le code tiré d’un fichier SVG.
C’est-à-dire que l’image SVG n’est plus chargée comme une image - à la manière d’une image JPEG, mais directement intégrée à l’intérieur du HTML. Il y a deux intérêts :
– le chargement de l’image SVG se fait en même temps que la page HTML, donc sans attendre ; c’est intéressant pour les « petits » fichiers SVG, typiquement des éléments de l’interface, qui s’affichent ainsi instantanément dans la page ;
– c’est indispensable si on veut modifier les couleurs des éléments SVG directement dans les CSS de la page. (Je le fais beaucoup, par exemple un bouton inverse ses couleurs au survol.)
L’originalité par rapport à d’autres fonctions équivalentes que j’ai vu passer, c’est que l’insertion est ici responsive (elle occupe 100% de la largeur disponible), il faut donc soi-même indiquer les éventuelles dimensions d’affichage désirées. Pour que cela fonctionne, la fonction est capable d’extraire les valeurs de la viewBox du fichier SVG et de fabriquer un <span> englobant qui rend l’affichage responsive.
Ça s’utilise ainsi :
[(#CHEMIN{hamburger.svg}|include_svg)]Dans la version 1.34 que je viens d’installer, la fonction gère une variable $alt :
[(#CHEMIN{hamburger.svg}|include_svg{Menu})]Si on ne renseigne pas ce texte, alors le <svg> est passé en role='presentation' et alt=''. Dans l’exemple ci-dessus, le bouton qui déclenche le hamburger contient déjà la mention « MENU » à côté du hamburger, il n’est donc pas intéressant d’afficher « MENU MENU ».
Si on renseigne ce texte, alors le <svg> est passé avec role='img' et la valeur alt=… est renseignée. Dans l’exemple ci-dessus, la mention « MENU » est donc directement associée à l’image du hamburger.
(Note : cette fonction était aussi présente de mon plugin Maquettes multiples. Je viens de l’en supprimer (parce que “Maquette multiples” fonctionne, idéalement, avec “Insertion avancée d’images”.)
SPIP propose déjà de base maintenant une fonction |balise_svg qui intègre directement dans le HTML, y compris avec un alt accessible. Il est aussi possible de forcer un taille.
▻https://www.spip.net/fr_article6511.html
et s’il manque des choses on peut l’améliorer :)
J’allais le dire, merci @rastapopoulos
et s’il manque des choses on peut l’améliorer :)
et s’il manque des choses on devrait l’améliorer :))
voir aussi l’indispensable plugin Z-core qui propose la balise #ICON qui fait idem une insertion « inline » d’un fichier SVG avec une class et un alt selon la syntaxe suivante :
#ICON{repertoire/fichier.svg, class, alt}
Dernière balise qui est censée être remplacée génériquement par l’implémentation finale de ce ticket… un jour :p
▻https://git.spip.net/spip/spip/issues/4727
Mise à jour de maintenance et sécurité : sortie de SPIP 4.2.8, SPIP 4.1.15
Ces nouvelles versions corrigent certains bugs et une petite faille de sécurité de type XSS. Un grand merci à Daniel Barros pour le signalement.
▻https://blog.spip.net/888 & ▻https://blog.spip.net/889
#spip




























{kind=link}