-
-


RAWGraphs
▻http://rawgraphs.ioThe missing link between #spreadsheets and data visualization.
#tableur #visualisation_de_données (via @Fil)
-
très facile à installer, configurer et étendre, mais il n’est pas le seul (voir aussi #Vega ►https://seenthis.net/messages/557875 )
-

-

Ici, un exemple... la composition de la population étrangère à Milan :
▻http://rawgraphs.io/learning/how-to-make-a-bump-chart
#rawgraphs
-
-
Émile Zola interviewé sur l’interview | Retronews
▻http://www.retronews.fr/actualite/%C3%A9mile-zola-interview%C3%A9-sur-linterview« — C’est une chose excessivement grave qui, pour être bien faite, exige d’énormes connaissances. Il faut avoir l’usage de la vie, savoir où l’on va, connaître – au moins par ses œuvres – l’homme chez qui l’on se rend, approfondir la question qu’on doit lui soumettre, savoir écouter, prendre tout ce que l’on vous dit, mais dans le sens où on le dit, interpréter avec sagacité et ne pas se contenter de reproduire textuellement. […] Non, l’interviewer ne doit pas être un vulgaire perroquet, il lui faut tout rétablir, le milieu, les circonstances, la physionomie de son interlocuteur, enfin faire œuvre d’homme de talent, tout en respectant la pensée d’autrui. »
-
British Newspaper Archive
▻http://www.britishnewspaperarchive.co.ukThe British Newspaper Archive is a partnership between the British Library and findmypast to digitise up to 40 million newspaper pages from the British Library’s vast collection over the next 10 years.
▻https://www.youtube.com/watch?v=xsSq06QLnXI
Et une étude “Content analysis of 150 years of British periodicals”
▻http://www.pnas.org/content/early/2017/01/03/1606380114.full.pdf -


WildLeaks is the world’s first, secure whistleblower initiative dedicated to Wildlife & Forest Crime.
▻https://wildleaks.org
#environnement #lanceurs_d'alerte
cc @odilon @reka @fil -



The Future of Social Audio is Here, Presenting the Audiogram Generator, by Delaney Simmons, Director of Social Media at WNYC ▻https://medium.com/@WNYC/socialaudio-e648e8a5f2e9
GitHub - nypublicradio/audiogram: Turn audio into a shareable video ▻https://github.com/labsletemps/audiogram
 https://cloud.githubusercontent.com/assets/2120446/17450988/7e6c4ea2-5b31-11e6-8f90-b32fec6864c3.gif
https://cloud.githubusercontent.com/assets/2120446/17450988/7e6c4ea2-5b31-11e6-8f90-b32fec6864c3.gif Unlike audio, video is a first-class citizen of social media. It’s easy to embed, share, autoplay, or play in a feed, and the major services are likely to improve their video experiences further over time.
Our solution to this problem at WNYC was this library. Given a piece of audio we want to share on social media, we can generate a video with that audio and some basic accompanying visuals: a waveform of the audio, a theme for the show it comes from, and a caption.
For more on the backstory behind audiograms, read this post.
-

J’ai l’impression que ça ressemble fort à ce qu’a commencé à faire This American Life (possibilité de « découper » un petit morceau d’émission pour le partager en ligne sous la forme d’un « audiogramme » > ▻https://shortcut.thisamericanlife.org/#/clipping/577/0?_k=wl50hn)
-
-
ce qui est un peu triste, je trouve, c’est de limiter les visualisations du son à cette forme très basique ; je suis sûr qu’il y a bien mieux à faire, comme on en a repéré déjà pas mal d’exemples ici sur les mots visualisation et musique :
▻https://seenthis.net/?page=recherche&recherche=visualisation+musique -
L’original c’est celui de la radio publique de New York : ►https://github.com/nypublicradio/audiogram
-
-
Mappable
►https://mappable.com▻https://www.youtube.com/watch?v=HH7vLTE58fw
concept : #machine_learning #musique avec une visualisation de proximités par des méthodes de #cartographie
-
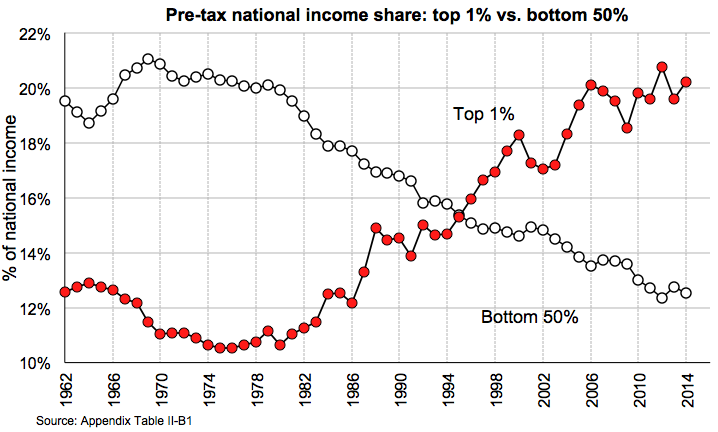
WID - World Wealth & Income Database
►http://wid.worldCompare inequality between countries on an interactive world map
Follow the evolution of inequality within countries with user-friendly graphs
Download our open-access datasets
THE SOURCE FOR GLOBAL INEQUALITY DATA
More than 100 top-level researchers involved, covering 70 countries over 5 continents. Entirely funded by public and non-profit actors.
-

Une initiative de plus parmi une multitude d’initiatives en générale très bien. Je me demande ce qu’on pourra bien faire comme carto dans un futur proche, bientôt tout sera sans doute couvert. Où alors pour créer des visions carto originales, il va falloir être très très très inventif :)
#cartographie #visualisation #statistiques #base_de_donnée #riches #pauvres #économie
-
-
With Zombie, Le Temps wants to give a second life to its evergreen stories – LE BAC À SABLE
▻https://blogs.letemps.ch/labs/2016/11/21/zombie-a-new-tool-to-give-a-second-life-to-le-temps-evergreen-stories/ampZombie will analyse articles on Le Temps’ website using data from both Chartbeat and Google Analytics. It will score each article according to its relevance and quality. This score will be calculated using the article’s reading time, viewing history and engagement on social media networks. Zombie will also identify key people, places and events mentioned in the article using semantic analysis APIs. It will create a database that, over time, will hold thousands of articles of interest that could be republished.
2. Several times a day, Zombie will see what the hottest topics are in Google Trends, Google News and Twitter’s Trending Topics. It will then check to see whether its database contains any articles related to these topics. If so, Zombie will alert Le Temps’ editorial staff in two ways: through a daily email with that day’s suggestions, and with Slack (serving as a real-time alert system).
Once alerted, the newspaper’s web editor and community manager can decide whether to republish the articles suggested by Zombie or repost them on social media.
-


Habeas corpus financé par la Digital News Initiative de Google (#DNI), branché sur google news et les trends de Twitter (oui, ce message est un peu sibyllin)
Sur le sujet, lire « L’opération pommade de Facebook & Google auprès des #médias »
▻http://lemonde.fr/actualite-medias/article/2017/01/14/l-operation-seduction-de-facebook-et-de-google-aupres-des-medias_5062641_323En témoigne l’annonce, mercredi 11 janvier, du Facebook Journalism Project, une série d’initiatives destinées à aider les éditeurs à mieux utiliser le réseau social. « Nous allons entamer une collaboration plus approfondie avec les médias », a indiqué Fidji Simo, responsable des produits vidéo du réseau social, dans un post de blog. Quelques jours plus tôt, l’entreprise nommait Campbell Brown – une ancienne journaliste sur les chaînes américaines CNN et NBC – « directrice des partenariats avec les médias ».
-


why not in français, tant qu’à faire ? :)
▻https://blogs.letemps.ch/labs/2016/11/21/avec-zombie-le-temps-veut-redonner-une-seconde-vie-a-ses-meilleurs-artet avec « amp » à la fin de l’url, c’est pour les mobiles ?
▻https://blogs.letemps.ch/labs/2016/11/21/avec-zombie-le-temps-veut-redonner-une-seconde-vie-a-ses-meilleurs-articles/ampby @jeanabbiateci !
-
Et un petit oiseau ▻https://twitter.com/ProjetZombie
-

Mwé. Reste la question : que faire des articles pertinents, de qualité, non répérés par les internets, ayant eu peu de succès mais méritant d’être ressuscités ?
-
-
rapport 2017 du google DNI
▻https://digitalnewsinitiative.com/documents/8/A4_DNI_280617_V9.pdfle round 4 va ouvrir avec l’accent sur la #monétisation, qui devient un composant obligatoire des projets soumis
-
-
Mémo Git
Récuperer un projet
git clone https://github.com/xx/xx.gitAjouter un fichier
git add index.htmlRenomer / déplacer
git mv source destCommiter
git commit -m "ajout d'un fichier index"
git pushCréer un projet et le commiter
cd path/to/directory
git init . #Initiate a git repository
git add . #Add existing files
git commit -a -m "commit message goes here" #Commit all files (-a) and add a message (-m) -
▻https://gist.github.com/cobyism/4730490
Deploying a subfolder to GitHub PagesSometimes you want to have a subdirectory on the master branch be the root directory of a repository’s gh-pages branch. This is useful for things like sites developed with Yeoman, or if you have a Jekyll site contained in the master branch alongside the rest of your code.
For the sake of this example, let’s pretend the subfolder containing your site is named dist.
You might then push : ▻https://github.com/Financial-Times/cardkit
-
ça me semble un peu daté car désormais on peut publier depuis le répertoire
docsde la branchemaster.Configuring a publishing source for GitHub Pages - User Documentation
▻https://help.github.com/articles/configuring-a-publishing-source-for-github-pagesYou can configure GitHub Pages to publish your site’s source files from master, gh-pages, or a /docs folder on your master branch
-
-
-

The Rise and Fall of .Ly
▻http://priceonomics.com/the-rise-and-fall-of-lyThe start-up Letter.ly also announced that it had gone down because it had let its domain registration expire, and it could not establish contact with the registrar to renew it’s contract. “Sorry for the hassle,” they wrote in an email to their users. “it’s amazing that a physical war has affected our service in this way.”
(…)
Aerial view of one of the islands, Diego Garcia, showing military base.
“.io is a place, but you can’t go there,” Bridle writes , “unless you’re serving in the military, sailing your own yacht, or in chains. The only way the rest of us can reach it is through the Internet.”Like Libya, the British Indian Ocean Territory is another example of how a cool-sounding abbreviation in a URL can mask a complex situation in the real world. And there are dangers to that. The more obscure countries of the world are selling their names away as branding tools. In such a system, it’s easy to lose sight of the very real geographic and political dimensions to a domain name.
-

-

seenthis.io, ça serait bien, pourtant.
-

-

ah merci @maliciarogue : très pertinentes critiques, et je découvre au passage que tu as écrit un livre sur #D3.js ❤️ ?
-
:) ouiiii ! Et j’en ai autre qui vient, avec @stephane dedans (mais sans D3.js cette fois).
-
-
-
This is just amazing. Search for anything said on any TV program from the US since 2009, watch that moment, and cite it.
Jason Scott @textfiles> Let’s be clear; you can search 8 years of news programs by caption. Right now. Immediately. And quote what you find. ▻https://archive.org/details/tv
-
textkit : Command line text processing — textkit 0.0.1 documentation
▻http://learntextvis.github.io/textkittextkit: Command line text processing
#textkit is a set of command line tools for text processing and analysis.
You can use it to do basic natural language processing from the command line.
voir aussi : ▻https://seenthis.net/messages/558636
-
Irene Ros — Text is data ! Analysis and visualization methods (PLOTCON 2016)
▻https://www.youtube.com/watch?v=4f6nOjQXSaUet le joli projet #textkit qui fait un peut comme #csvkit, mais pour #nltk et le #text-mining
▻https://github.com/learntextvis/textkit
Andy Kirk - The Design of Nothing : Null, Zero, Blank (OpenViz Conf)
►https://www.youtube.com/watch?v=JqzAuqNPYVM-
PLOTCON 2016 : Peter Wang, Interactive Viz of a Billion Points with Bokeh Datashader - YouTube
▻https://www.youtube.com/watch?v=fB3cUrwxMVYun outil pour plotter des #millions de données directement sur l’écran, ce qui permet des analyses étonnantes (vers la fin, une démonstration du gerrymandering, très impressionnante)
-
dans cette présentation de Michael Freeman, on parle un peu de #d3.js mais surtout des concepts qu’il s’agit de représenter.
Deux exemples d’infographies frappantes concernant les #États-Unis :les morts par arme à feu
►http://guns.periscopic.com/?year=2013ce projet qui montre la ségrégation raciale à travers l’"explosion" des villes
▻http://vallandingham.me/racial_divide -
démo d’un système de #base_de_données cartographique hyper-rapide, basé sur #GPU :
▻https://www.mapd.com
▻https://www.youtube.com/watch?v=9z-nHmEm5JEvers la fin on voit comment Facebook, Twitter etc. ont un accès instantané, à travers divers filtres, à l’ensemble des centaines de millions d’infos qu’ils collectent en temps réel
-
-

How Do Americans Get Rich? (And Stay Rich?)
▻http://www.nakedcapitalism.com/2017/01/americans-get-rich-stay-rich.htmlWe pay people for doing things, and we pay people for owning things. Increasingly, the latter.
-
jakob/TableTool: A simple CSV editor for the Mac
▻https://github.com/jakob/TableToolA simple #CSV editor for OS X.
brew cask install table-tool-
OS X 10.10+
il est envisagé d’étendre à OS X 10.9, voire 10.7, mais je suis encore en dessous…
Dommage. -


@simplicissimus A propos de 10.7 : j’ai remis à neuf (batterie, disque dur, RAM, et réinstall complète) le Macbook blanc de ma soeur (qui ne peut dépasser le 10.7). Tout marche très bien, sauf les navigateurs Web qui refusent de s’installer (Chrome et les nouveaux Firefox exigent 10.9 minimum) ou fonctionnent moyen (rendu Safari médiocre). Qu’utilises-tu comme navigateur ? Merci.
-
J’ai un Mac Mini (mid-2011) sur lequel tournent OS X 10.7.5
– Chrome 49.0 (2017)
– Safari 6.1.6 (2014)et un MacBook (late-2008) sous OS X 10.5.8, avec
– Chrome 21.0 (2011)
– Safari 5.0.6 (2011)Pas de MàJ possible (système ou navigateur). Mais tout ça marche suffisamment bien (et vite) pour que je n’éprouve pas le besoin de changer de machines, d’autant plus que, l’âge venant, l’attrait des super hautes résolutions Retina est de moins en moins sensible.
Sauf, évidemment, les navigateurs. Sur le MacBook, j’ai des problèmes de rendu (mais Safari s’en sort mieux que Chrome), de lecture de vidéo (Chrome les refuse sauf quelques embedded, dont celles dans ST, en général Safari s’en sort) et, pour des raisons que je n’arrive pas à identifier, pendant tout un moment je n’arrivais plus à accéder aux pages https (certificat non reconnu) avec Chrome. En ce moment, ça marche (je croise les doigts) parce que (je pense…) j’ai été forcer manuellement l’acceptation des certificats sous Safari, ce que Chrome ne me propose pas.
-

Il est possible que certaines versions d’Opera avant qu’ils ne basculent à Chromium puissent marcher très correctement. Je n’ai pas de 10.7 pour tester mais peut-être ▻http://arc.opera.com/pub/opera/mac/1216 ? (Sinon il y a d’autres versions sur le même serveur).
Pour les certificats, les fois où j’ai eu des problèmes de ce genre c’était parce que l’horloge de ma machine s’était trop décalée par rapport à l’heure réelle (notament une vieille petite tablette qui pour des raisons obscures refuse de faire du NTP). Chrome est super-strict là-dessus.
Pour la vidéo il y a peut-être moyen d’écrire une petite extension qui chope l’URL source et ouvre VLC dessus.
-
Merci, j’essaierai Opéra quand j’aurai le Macbook sous la main. J’avais trouvé aussi un « Firefox ESR » (extended support release), mais ils annonçaient discontinuer la 10.7 en 2017. C’est très curieux cette limitation des MacOS, j’ai un Macbook Pro de fin 2011 que j’ai pu passer en Sierra sans souci, mais la génération des Macbook blanc et noir refuse d’aller au-delà de la 10.7, je ne sais pas pourquoi.
-
C’est pas tout simplement parce que c’est la dernière génération PowerPC ?
-
Non non, c’est un « Macbook3.1 », ce sont des Intel Core Duo... Apparemment le saut à Mavericks ne se fait que sur les modèles depuis 2009, mais à voir les différences de spécs techniques ça a l’air vraiment minime (la seule explication que je trouve c’est le passage de cartes graphiques Intel GMA avant, à des cartes NVIDIA après - ils auraient pu faire un effort, mais n’en avaient sûrement pas envie...). ▻https://en.wikipedia.org/wiki/MacBook
-
-
-
-
voir aussi #textql, qui semble faire un peu pareil ▻http://seenthis.net/messages/225658
-
-
-

Thimbl - Free Open Source Distributed Micro-blogging
►http://www.thimbl.netWelcome to Thimbl, the free, open source, distributed micro-blogging platform. If you’re weary of corporations hi-jacking your updates to make money, or if being locked in to one micro-blogging platform tires you — well, then Thimbl is for you!
-
Cela semble très intéressant. Le principal point que j’ai noté est qu’ils affirment bien haut qu’ils ne font rien de nouveau : l’Internet a toujours été un réseau social et Usenet, le courrier et IRC [ils auraient pu citer XMPP aussi, NDLR] sont bien plus avancés techniquement que Facebook et twitter, puisqu’ils permettent l’interaction distribuée depuis longtemps.
Fort logiquement, leur système repose donc sur des technologies distribuées existantes, #SSH et #finger.
À noter également une très juste critique de #status.net, qui n’est pas une vraie fédération (chacun peut installer son instance de status.net, comme le fait identi.ca mais pas moyen de les faires interagir proprement puisque les identificateurs sont purement locaux). status.net est donc un recul par rapport au courrier ou à XMPP.
-
-
-
csvkit 1.0.1 — csvkit 1.0.1 documentation
▻http://csvkit.readthedocs.io/en/1.0.1/index.htmlcsvkit is a suite of command-line tools for converting to and working with CSV, the king of tabular file formats.
-

-
Ah oui super.
Je viens de découvrir un truc dingue. Excel suppose que puisqu’on est en France, le séparateur de champs d’un fichier
csvest non pas,mais;...Du coup si quelqu’un nous envoie un véritable fichier
csvet bien il ne s’ouvre pas dans Excel FR.A moins de faire :
csvformat -D \; "$source" > "$source.tmp"
mv "$source.tmp" "$source"De même pour convertir un fichier excel en fichier « csv » à la mode excel FR :
source="$1"
dest="${1/xlsx/csv}"
in2csv "$source" > "$dest.tmp"
csvformat -D \; "$dest.tmp" > "$dest"
rm "$dest.tmp" -
LibreOffice à la bonne intention de te demander quel est le séparateur utilisé dans les csv lors de leur ouverture ;)
-
@booz, pour ouvrir un fichier .csv avec Excel, il faut préalablement le renommer en .txt ce qui te donne la main sur le choix du séparateur (et des jeux de caractères).
Tu peux aussi (et ça marche aussi pour l’enregistrement d’Excel vers le csv) dire à ton ordi qu’il n’est pas en France (paramètres régionaux sous Windows ou préférences sous MacOS).
-
Héhé, et pour gérer les accents sous Mac dans un viel excel, faut en plus faire :
| iconv -f UTF-8 -t macintoshDonc pour convertir un
csvpropre en Excel FR à l’ancienne et que ça s’ouvre en cliquant dessus sans rien faire d’autre :csvformat -D \; "$source" | iconv -f UTF-8 -t macintosh > "$dest"Et bonus, une version en spip/php pour générer un fichier à télécharger qui sera ouvert dans Excel avec les bons accents que @fil m’avait fait il y a quelques années.
Dans
mon_squelette_fonctions.php:<?php
include_spip('inc/charsets');
init_mb_string();
ob_start('convert_utf16');
function convert_utf16($txt) {
return "\xFF\xFE" . mb_convert_encoding("\n".$txt, 'UTF-16LE', 'UTF-8');
}Dans
mon_squelette.xls.html:#HTTP_HEADER{Content-Type: application/vnd.ms-excel; charset=UTF-16LE}
... -
En fait Excel n’est pas si mauvais que ca. J’ai compris que le coup du séparateur
;avait sont intérêt enfrcar la,est utilisée pour les nombres décimaux en francais (c’est un.en anglais). Donc pour parser un fichier csv c’est plus simple avec des donnéesfrsi le séparateur est;pour ne pas confondre un champs et un nombre décimal.Par ailleurs j’ai testé
csvkitvsExcelvsGooglesheetsvsawkavec un fichier csv de 11Mo, et bien C’estExcelqui s’en sort le mieux.csvkitetGooglesheetsramment tant qu’ils peuvent,awks’en sort bien mais ne sait pas parser simplement sur les,en distinguant les,séparateurs de champs des,décimales.Excel gère...
Je me demande du coup si le bon format pour des gros fichiers ne serait pas des données séparées par des tabulations.
-
Je persiste à penser – mais en ce domaine comme dans d’autres, le plus court chemin est celui que l’on connaît – que le moyen le plus simple d’ouvrir un .csv avec Excel est de le mettre en .txt. Tu passes ainsi par l’assistant d’importation de texte qui est court-circuité pour les .csv. Ses 3 étapes te permettent de choisir interactivement (tu visualises le résultat directement)
• le codage du texte et la ligne de début de l’importation
• le ou les séparateur(s) (ou le découpage en colonnes si tu es en largeur fixe)
• et (surtout !) le type de données pour chaque colonne (indispensable pour gérer les différents formats de date), voire de ne pas importer les colonnes qui ne t’intéressent pas (très utile pour les gros fichiers de données : quand tu supprimes les colonnes d’un tableau Excel, l’espace mémoire n’est libéré que lors de l’enregistrement du fichier, les colonnes que tu as importées puis immédiatement supprimées occupent toujours la mémoire).
-
-
-

J’ai proposé sous forme de jeu à énigme la chose sur la Wikipédia francophone (je dévoilerai demain la source). Une liste concurrente a été générée via Wikidata par un contributeur pseudommé Poulpy : ▻http://tinyurl.com/hzcdxhq (notons que SPARQL permet de faire le filtrage des accents).
-
-
-
pigshell - unix the web
▻http://pigshell.comResources on the web are represented as files in a hierarchical file system. These include public web pages as well as your data on Facebook, Google drive and Picasa albums. Construct pipelines of simple unix-style commands to filter, transform and display your files.
#web #outils #cli #bizarre #cartographie #data
hgrep
▻https://www.npmjs.com/package/hgrephgrep is a Unix CLI tool which lets you select elements with jQuery/CSS syntax and print either the HTML serialization of the selection, or a specified attribute of each element, or their text representation.
For example, to print all the story links from the HN front page:
curl -s https://news.ycombinator.com | hgrep -a href ".athing .title > a"
-

le guide de l’utilisateur : ▻http://pigshell.com/v/0.6.4/usr/doc/pigshell.html
=> ça reste un truc pour les forcenés/ultimes de la ligne de commande !
...mais avec un peu de métier ça doit être rudement pratique pour de la récupération/sauvegardes/archivage de données en ligne :ls /gdrive/username@gmail.com | grep -f mime spreadsheet | grep -e ’x.mtime > Date.parse("Dec 31, 2013")’ | cp .
The above command finds all files in the given user’s GDrive containing the string “spreadsheet” in their mime property, selects those files which those files modified since Dec 31, 2013 and copies them to the current directory.
-
-

Wikidata Query Service
▻https://twitter.com/WikidataFacts/status/814075781957746689
# Ratio of famous people’s deaths against all deaths since 2000.
# A person is (somewhat arbitrarily) considered to be famous if they have 25 or more sitelinks.
#defaultView:LineChart
SELECT
(STR(?year) AS ?year_) # STR(): work around T150515
# uncomment the below three lines for a more useful Table view
#(SUM(?famous) AS ?famousCount)
#(COUNT(person) AS ?totalCount)
#(?famousCount/?totalCount AS ?ratio)
# this line compresses the above three lines into one because otherwise the Line Chart would display ?famousCount whereas we want ?ratio
(SUM(?famous)/COUNT(?person) AS ?ratio)
WHERE {
?person wdt:P31 wd:Q5;
wdt:P570 ?died;
wikibase:sitelinks ?sitelinks.
FILTER(?died >= "2000-01-01"^^xsd:dateTime).
BIND(YEAR(?died) AS ?year).
BIND(IF(?sitelinks >= 25, 1, 0) AS ?famous).
}
GROUP BY ?year
ORDER BY ?year-
-
Visiblement ça utilise le langage #SPARQL
-
Hop, justement, un article sur SPARQL sort aujourd’hui sur linuxfr.org :
SPARQL le SQL du web, et Linked Data Fragment : le point sur le requêtage du web
▻http://linuxfr.org/news/sparql-le-sql-du-web-et-linked-data-fragment-le-point-sur-le-requetage-du-w
-