
#database
-
-

Données dispos par ici (après création rapide d’une clé d’API) :
▻http://opencellid.org/downloads
cell_towers.csv.gz 2015-03-04 04:06:46 158.3 MBHa oui tout de même... ^^
#map
-
-
OpenCage Geocoder - Credits
▻http://geocoder.opencagedata.com/credits.htmlListe de bases de données pour #geocoding
-

ADA Archive of Digital Art is online
▻https://www.digitalartarchive.at#art #digital_art #database #ada #archive
-

#database-antipattern - IndieWebCamp
▻http://indiewebcamp.com/database-antipatternUsing databases for the primary storage of content on your personal site is considered by some in the community to be an antipattern.
Common #CMS (e.g. WordPress, Drupal, MediaWiki, etc.) use databases for primary storage of content. Most often MySQL, sometimes others like MongoDB.
Databases are all a pain to maintain (i.e. highly human-time inefficient - see DBA tax below), and more fragile[1] than the file system.
For any content you care about, don’t put the primary copy in a #database.cc: #SPIP
-
flat files first, database for cache and search
Databases are useful for caching/performance needs for high volume sites. Examples:
– aggregations (e.g. all of your posts with a specific tag) can be cached.
– full-text search index
– geo-search indexIn both search use-cases the DBs should be a cache/query store, the real data should still be in flat files (e.g. .md, HTML, etc.) to ensure long-term durability.
-
-

Je suis relativement d’accord aussi, mais je me pose toujours la question de ce qui doit être mis dans le fichier plat lorsqu’il s’agit de liens de contenus qui ont eux-même plein d’autres attributs possibles.
Par exemple pour les cas courants des auteurs ou des mots-clés, est-ce que le fichier plat d’un article ne doit contenir que le nom/titre, ou bien aussi inclure tous les attributs des objets liés en plus ?
La solution est peut-être de suivre comme dans les liens Atom (principe repris dans plusieurs normes JSON aussi comme « Collection+JSON ») : que lorsqu’on indique un lien, on donne l’identifiant URI de l’objet lié ET un titre (et le typage du lien évidemment). Ce qui permet dans la majorité des cas d’afficher directement quelque chose sans autre requête (afficher en bas la liste des auteurs par ex). Mais SI on veut plus, on à l’URI des auteurs pour aller requêter leur fiche complète.
Par exemple on ne mettra pas :
titre: 'Mon article',
texte: 'Mon texte',
auteurs: ['Machine', 'Machin']Mais plutôt :
titre: 'Mon article',
texte: 'Mon texte',
links: [
{rel: 'auteur', title: 'Machine', href: 'URI'},
{rel: 'auteur', title: 'Machin', href: 'URI'},
] -
-

#phpcr, c’est bien aussi.
►http://phpcr.github.io -

-

Ben là, pour ce qui est des liens, c’est un standard @fil, ce sont les « web links » définies par plusieurs RFC, et utilisés dans Atom et dans de nombreux autres formalismes.
-
-

Do you have dirty data ? How dirty ? Find out quickly with #CSV Fingerprints !
▻http://setosa.io/blog/2014/08/03/csv-fingerprints #MDM #databases -
Data modeling in #graph #databases:
▻http://www.infoq.com/articles/data-modeling-graph-databases #Neo4jLots of good tips !
-

Décidément, ces temps, l’Australie et les réfugiés, c’est pas une bonne combinaison...
Immigration Department data lapse reveals asylum seekers’ personal detailsExclusive : online database provides personal details of almost 10,000 people in serious and embarrassing security breach
▻http://www.theguardian.com/world/2014/feb/19/asylum-seekers-identities-revealed-in-immigration-department-data-lapse
#database #asile #réfugiés #privacy #migration #Australie #données_personnelles #vie_privée #identité_online
-

DIFIRO :: Directory of InterFaith / InterReligious Organizations
▻http://interfaithdirectory.org
Interfaith Organizations identifying with frequently used WORDS as shown by size/count on hover, click one to view list of these, and their goals.
#religions #paix #conflits #dialogue_inter_religieux #database
#statistiques #data -

Australian immigration detention centres : every incident mapped
A vast dataset, which details every incident reported in each operational immigration detention facility in Australia between October 2009 and May 2011, shows the number of logged incidents - including self-harm, assaults, hunger strikes and damage as well as minor incidents - across much of Australia’s immigration detention network.
►http://www.theguardian.com/news/datablog/interactive/2013/jun/12/immigration-detention-centres-mapped-interactive
#cartographie #décès #accidents #centres_de_rétention #centres_de_détention #Australie #visualisation #carte #cartographie_interactive #database #base_de_données
cc @reka
-
Today’s Complex Data Can Help Predict the Future’s War Zones, by Jonathan Keats - Wired
▻http://www.wired.com/dangerroom/2013/10/afghanwarmaps
#GDELTFOR MUCH OF the past decade, Afghanistan’s remote Faizabad district remained out of the Taliban’s reach. But the northeastern region has become a target for violence—and according to a new predictive model, Faizabad could get dicey by mid-2014.
Led by PennState political scientist Philip Schrodt, a team of researchers developed the Global #Database of Events, Language, and Tone to scrape news from the Internet—the BBC, yes, but also hyperlocal sources around the world (...)The map below (...) forecasts conflict levels in #Afghanistan for June 2014.
-
New project aims to connect the dots in open data - Knight Foundation
▻http://www.knightfoundation.org/blogs/knightblog/2013/10/28/new-project-aims-connect-dots-open-data
Via Flowing Data
first proposed the idea of the U.S. Open Data Institute to Knight Foundation in the spring. Knight immediately supported the concept and nurtured the organization into existence. And now we’re getting to work.
I’m convinced that we already have many of the right people, organizations and businesses working on open data in the United States. They just don’t know about each other. (The organization certainly won’t duplicate any of the efforts of the folks in this space.) And we have nearly all of the necessary software, but so much of it is only known within its narrow domain, despite its broad applicability. The institute will connect all of these entities, promote the work of those who are leading the way and provide supportive, nonjudgmental assistance to those who need help. We don’t have all the answers, but we know the folks who do. We want to amplify their message and connect them to new collaborators and clients.
#open_data #statistiques #cartographie #visualisation #database #base_de_données
-
The World Top Incomes Database
▻http://topincomes.g-mond.parisschoolofeconomics.eu/#Introduction :
C’est Jean Abbiateci qui signale sur facebook l’énorme base de données de Piketty sur les inégalités et les revenus par tranche depuis plus d’un siècle
There has been a marked revival of interest in the study of the distribution of top incomes using tax data. Beginning with the research by Thomas Piketty (2001, 2003) of the long-run distribution of top incomes in France, a succession of studies has constructed top income share time series over the long-run for more than twenty countries to date. These projects have generated a large volume of data, which are intended as a research resource for further analysis.
#statistiques #bases_de_donnée #database #inégalités #revenus #piketty
-
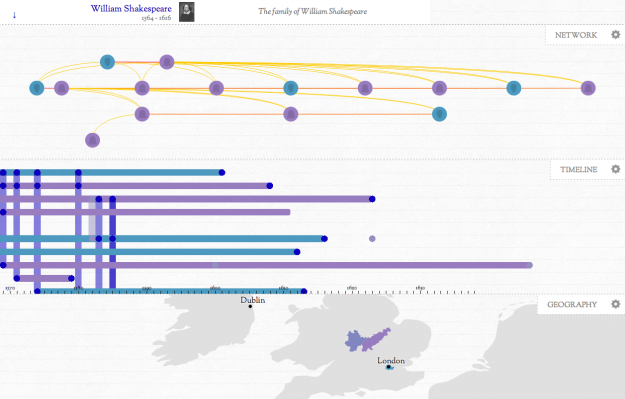
British relationships throughout history
▻http://flowingdata.com/2013/08/26/british-relationships-throughout-history
Kindred Britain assembles and visualizes records of nearly 30,000 individuals, mainly (but not exclusively) British. Many of them are extremely well-known in the nation’s culture. The database in its entirety spans more than 1,500 years, but the time-period of densest concentration comes in the 19th century. Any person recorded here can be connected to any other person in the network through family relationships of ancestry, descent, siblinghood, marriage or some other type of familial affiliation. In Kindred Britain, family is all. The site is a panorama of engineers and painters, novelists and generals, scientists and merchants, and even a few reprobates, misanthropes and monsters.
#cartographie #visualisation #réseaux #database #base_de Données #big_data
-
European Database of Asylum Law (EDAL)
▻http://www.asylumlawdatabase.eu
#database #base_de_données #asile #loi #EDAL #migration #réfugiés #répertoire
-
Mapping asylum procedures, reception conditions and detention in Europe
AIDA: asylum information #database
▻http://www.asylumineurope.org
#carte #cartographie #asile #base_de_données #réfugiés #détention #rétention #procédures #accueil #Europe #comparaison_européenne
-
#RethinkDB - an open-source distributed #database
►http://www.rethinkdb.comAn open-source distributed database (...) intuitive query language, automatically parallelized queries, and simple administration.
dans la veine du #NoSQL avec la possibilité de tranquillement faire du #map-reduce
-

Manage Your Database with Adminer | Linux.com
►https://www.linux.com/learn/tutorials/566420-manage-your-database-with-adminerIf you’re looking for a simple way to manage your database effectively, you might want to have a look at Adminer. It’s simple to install, supports multiple databases, and has a number of features you don’t find in phpMyAdmin.
-

Merci, c’est super-rapide. Je n’ai pas encore pu beaucoup le tester, mais #Adminer a l’air de faire tout dont j’ai besoin en plus simple et rapide que MyPhpAdmin.
Son seul défaut c’est la double licence Apache/GNU qui risque de créer des conflits dans l’avenir. Les auteurs considèrent que c’est un avantage par rapport à MyPhpAdmin qui n’est distribué que sous GNU. Je comprends leur point de vue mais je ne le partage pas.
-
Perso j’ai du mal à saisir cette histoire de double licences...
Il me semble que le seul intérêt est de pouvoir embarquer le code dans un produit propriétaire, ou de faire un dérivé commercial du soft...
-


@aris Oui, bien résumé la double licence (qui vaut quand même mieux que la double peine).
-
Une chose que PhpMyAdmin ne fait pas : importer des dumps présents sur le serveur.
-
-
-
What is Amazon DynamoDB?
►http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/Introduction.html#Amazon #DynamoDB is a fully managed #NoSQL #database service that provides fast and predictable performance with seamless scalability. If you are a developer, you can use Amazon DynamoDB to create a database table that can store and retrieve any amount of data, and serve any level of request traffic. Amazon DynamoDB automatically spreads the data and traffic for the table over a sufficient number of servers to handle the request capacity specified by the customer and the amount of data stored, while maintaining consistent and fast performance.
-
The Ten Most Amazing #Databases in the World | Popular Science
►http://www.popsci.com/technology/article/2011-10/ten-most-amazing-databases-worldThe Combined DNA Index System
The Encyclopedia of Life
The Food and Agriculture Organization Database
The Genographic Project
The International Panel on Climate Change’s Data Distribution Centre
The MD:Pro
OKCupid’s OKTrends
Sloan Digital Sky Survey Database
The Wayback Machine
WorldCat -
parallel-flickr
►http://straup.github.com/parallel-flickrparallel-flickr is a tool for backing up your #Flickr photos and generating a #database backed website that honours the viewing permissions you’ve chosen on Flickr.
via @karlpro
(à noter que je fais déjà ça chez moi avec mon script flickrstore) -
Étude de la BNF sur les archives de l’Internet | Construction de ses autorités cognitives
►http://gnm.hypotheses.org/1497Étude de la BNF sur les archives de l’Internet
22 juin 2011
Par Guillaume-Nicolas MEYERCette étude prospective sur les représentations et les attentes des utilisateurs potentiels a le mérite de présenter le principe des archives, leur fonctionnement et de mettre en avant un certain nombre de questions pertinentes.
Le web est pour beaucoup de professionnels (veille, e-reputation, communication, marketing) un terrain de recherche. En partant de ce constat, quel sens cela fait-il d’envisager d’archiver le web ? Cela est-il possible ? Dans quelles conditions et pour quels usages ?
Qu’est-ce que le web ?pour @fil
#internet #archives #basededonnées #database #bibliothèque
Tout d’abord, quelles représentations nous faisons-nous d’hypothétiques archives du web ? A cette première question, le principe « méconnu » du fonctionnement des moteurs de recherche ainsi que les « archives » proposées par le moindre blog ou site institutionnel viennent brouiller la perception du tout venant puisqu’elle donne l’illusion d’un auto-archivage du web de par son fonctionnement même.
Ensuite, le web est un espace infini et pourtant chaque utilisateur a « son » propre web. Même les chercheurs et les spécialistes de l’information développent des réseaux « égocentrés », qui sont, autant de frein à une perception plus large du web. L’univers est infini, mais au final, à part notre système solaire, qu’est-ce que chacun d’entre nous en a comme perception de cet infini ?
Flux continu mouvant et archive figéesLa principale question qui me vient à la lecture de ce document : au-delà de la capacité à « capturer » une portion de web, quel sens cela fait-il d’archiver une portion du web sans le reste de son environnement ?
Ne risque t’on pas de déformer une information en la coupant de son contexte ? Encore plus qu’ailleurs, une information sur le web, ne peut pas être définie comme pertinente, populaire, influente, crédible, fiable, de qualité, sans la contextualiser. Ôter le flux de son environnement est à mon sens plus dommageable que souhaitable. De plus « on se retrouve devant un autre problème, philosophiquement très intéressant, c’est qu’on ne peut pas archiver du flux. » Comme le fait remarquer un des participants à l’étude, le web relève plus de la tradition orale qu’écrite. Dans ce sens, le web évolue tout les jours. Au-delà des ajouts faramineux de contenu (plusieurs heures de vidéos sont mis en ligne chaque minute sur YouTube), le contenu existant est largement modifié. Une page que vous avez vu hier peut être très différente aujourd’hui, voire ne plus exister.
-

L’INA aussi vient de publier son enquête (en charge du dépôt légal web de l’audiovisuel)
« Un Web archivé pourquoi faire ? »
►http://atelier-dlweb.fr/blog/?p=574
Autrement j’avais aussi vu passer ce billet d’O. Le Deuff, qui cite la même étude de la BnF :
►http://www.guidedesegares.info/2011/06/08/amorcer-la-reflexion-sur-larchivage-du-web
Et puis, je signale, dimanche dans "place de la toile", "archiver le web" avec un entretien de B. Kahle et deux ingénieurs de l’INA :
►http://www.franceculture.com/emission-place-de-la-toile-archiver-le-web-le-hacking-artistique-de-z
Tu connais bien le sujet @fil ? (je prépare un papier pour septembre...) #dépôt_légal
-
« bien », non, mais j’ai participé à un précédent colloque de la BNF sur le sujet (►http://www.bnf.fr/documents/cp_memoire_web_sites_electoraux.pdf ), notamment à propos de l’archivage du web militant (pour listes.rezo.net)
-
L’article en question, 6 mois plus tard...
La Toile retrouve la mémoire
►http://www.ecrans.fr/La-Toile-retrouve-la-memoire,13683.html #shameless_autopromo
-
-
Create web applications stored in an Apache CouchDB database | Martin Brown
►http://www.ibm.com/developerworks/opensource/tutorials/os-couchapp/index.html?cmp=dw&cpb=dwope&ct=dwnew&cr=dwnen&ccy=zz&csr=05Apache #CouchDB is an open source document-oriented #database management system that allows you to create full database-driven applications using nothing but HTML, CSS and JavaScript. In this tutorial, you will learn how to create your own #CouchApp that will perform database operations using #Ajax powered by the #jQuery framework. The application you will build is a contact manager that allows you to view, create, edit, and delete your contacts.
-

UNdata
►http://data.un.orgDonnées des Nations Unies. Possède son API (non officielle)
#data #database #datamining #world #api #resources #statistics #nations_unies
-
Google - public data
►http://www.google.com/publicdata/home#google #data #visualization #research #tools #database #statistics





















{kind=link}