HipHop
►http://gethiphop.net
HipHop is an application for Windows, Mac and Linux that lets you listen instantly to more than 45 million songs (way more than iTunes that has only 26 million). It requires no sign up, displays no ads and is 100% safe.
HipHop
►http://gethiphop.net
HipHop is an application for Windows, Mac and Linux that lets you listen instantly to more than 45 million songs (way more than iTunes that has only 26 million). It requires no sign up, displays no ads and is 100% safe.


On me souffle que c’est fait avec #node-webkit... (comme popcorn au début).

Je ne trouve pas d’explication de comment ça marche juridiquement/économiquement.
Car pour avoir le droit légal de diffuser toutes ces musiques, même en streaming, il faut bien des accords (financiers) avec les éditeurs et artistes, non ? Donc c’est quoi l’astuce là ?

Chez Korben
HipHop - Un clone de PopCorn Time mais pour la musique « Korben
▻http://korben.info/hiphop-clone-popcorn-time-musique.html
Oui, HipHop propose 45 millions de chansons en allant choper le son des vidéos YouTube. Il choisit celles qui sont de la meilleure qualité possible et vous propose tout cela sans pub et sans inscription.
(…)
Reste à savoir maintenant combien de temps ce service va durer. Google pourrait lui fermer le robinet et surtout les ayants droit pourraient mettre leurs avocats sur le coup histoire de tuer dans l’oeuf cette appli. L’avenir nous le dira.
Ok ok, là c’est pas par Torrent, c’est en pompant le son de Youtube. Ouais, ça risque de pas durer longtemps…

Pour Popcorn, j’ai testé le PPA pour Ubuntu qui existe toujours, et ça marche vraiment très bien aussi, y compris avec sous-titres fr.
Mais par contre, faut pas essayer de chercher autre chose qu’un film anglo-saxon…
#dead
HipHop started as a technical challenge between friends. The recent success wasn’t expected, and we took the entire project down this morning.
We are all users of paid music services and we do believe in artists getting paid for their creations.
If you do like music, there is a lot of amazing services out there: Deezer, Spotify, Rdio, ...
Haha, ça a tenu moins longtemps que Popcorn.

Pour le moment ça fonctionne toujours très bien quand même, conservez précieusement le binaire (et les sources) :)
Héhé oui c’est ce que j’ai fait aussi. :)
Je ne sais pas chez vous, mais là j’ai l’impression que la lecture ne se lance plus. Du genre Youtube a bloqué tout streaming demandé par ce client. (Popcorn basé sur torrent, lui fonctionne toujours bien. :-)
Parfait :) Effectivement HipHop ne fonctionnait plus.

Un Livre Un Jour
▻http://programmes.france3.fr/livres/un-livre-un-jour/evenements
Nous sommes allés à la bibliothèque Louise Michel, Paris XXème, rencontrer Julien Prost et parler avec lui des bouleversements que subissent ces établissements publics face à l’avènement du numérique.
Comment continuer à faire de cet espace un lieu de convivialité, ouvert sur la cité et au service du quartier à l’heure où le livre numérique est rentré dans les foyers ?
Quelles sont les transformations du métier même de bibliothécaire aujourd’hui ?
Family Movie & Artefacts - super 8 - macrophotographie
▻http://www.super8artefacts.com/#series-artefacts
Depuis des années nous voyons passer devant nos yeux des images fugitives de brûlures, des altérations du temps, des curiosités.
Un jour, nous avons pris la décision de regarder de plus près. Vraiment plus près.
Immersion dans un univers abstrait insoupçonnable.
Taux d’emprunt immobilier : Il se pourrait bien que ce soit le meilleur moment pour acheter
▻http://www.huffingtonpost.fr/2014/06/04/taux-emprunt-immobilier-acheter-credit_n_5444910.html
les taux d’intérêt des crédits immobiliers accordés aux particuliers ont baissé à 2,85% en moyenne en mai.
....
S’il reste plus de 10 ans à rembourser sur son crédit et qu’il y a au moins 0,7 ou 0,8 point d’écart entre le taux actuel et le taux auquel vous avez emprunté, un rachat vaut certainement le coup
Privacy Badger | Electronic Frontier Foundation
▻https://www.eff.org/privacybadger#how_is_it_different
Privacy Badger was born out of our desire to be able to recommend a single extension that would automatically analyze and block any tracker or ad that violated the principle of user consent; which could function well without any settings, knowledge or configuration by the user; which is produced by an organization that is unambiguously working for its users rather than for advertisers; and which uses algorithmic methods to decide what is and isn’t tracking.
Although we like Disconnect, Adblock Plus, Ghostery and similar products (in fact Privacy Badger is based on the ABP code!), none of them are exactly what we were looking for. In our testing, all of them required some custom configuration to block non-consensual trackers. Several of these extensions have business models that we weren’t entirely comfortable with. And EFF hopes that by developing rigorous algorithmic and policy methods for detecting and preventing non-consensual tracking, we’ll produce a codebase that could in fact be adopted by those other extensions, or by mainstream browsers, to give users maximal control over who does and doesn’t get to know what they do online.
via @vincib
Le Mans. MMA va indemniser ses salariés qui viennent à vélo | Le Maine Libre
▻http://www.lemainelibre.fr/actualite/le-mans-mma-va-indemniser-ses-salaries-qui-viennent-a-velo-02-06-2014-9
Dans le cadre du plan d’actions sur les mobilités actives proposé par le ministre des transports, les MMA ont décidé d’expérimenter la prise en charge des indemnités kilométriques vélos de ses salariés sur 4 de ses sites, dont celui du Mans.


Je crois qu’il y a 2 sites (Calif. et la gare) au Mans.
Le site MMA du Mans où j’ai travaillé est bien excentré ...
▻http://fr.wikipedia.org/wiki/Quartier_Californie
ping @odilon ?

Oui, c’est bien ça, Californie et gare sud :) Celui gare sud est bien mieux desservi par les transports en commun que celui de Californie.
Les prestataires (qui ne bénéficieront pas, bien sûr, de l’indemnisation des MMA) du site de Californie vont avoir de belles jambes avec cette annonce ! :-)
TrueCrypt
▻http://truecrypt.sourceforge.net
WARNING: Using TrueCrypt is not secure as it may contain unfixed security issues
This page exists only to help migrate existing data encrypted by TrueCrypt.
The development of TrueCrypt was ended in 5/2014 after Microsoft terminated support of Windows XP. Windows 8/7/Vista and later offer integrated support for encrypted disks and virtual disk images. Such integrated support is also available on other platforms (click here for more information). You should migrate any data encrypted by TrueCrypt to encrypted disks or virtual disk images supported on your platform.
Migrating from TrueCrypt to BitLocker:
On ne sait pas encore si le site s’est fait hacker ou pas ... #a_suivre #ne_pas_bouger_pour_l'instant
#truecrypt

Le développement d’une #distribution #linux, ou même de tout projet logiciel open source, est quelque chose de fascinant lorsque l’équipe du projet se rencontre physiquement.
Pour le lancement de la version finale d’#OpenMandrivaLx nous étions ce week end 15 personnes (et un chien) réunis à Prague, venant de 12 pays différents. Un des contributeurs, habitant en Inde n’avait pas pu nous rejoindre car son visa lui avait été refusé, malgré toutes nos lettres d’explication, invitations professionnelles et autres paperasseries ("not reliable documents" selon l’ambassade de la République Tchèque, satané espace Shengen).
Outre la joie de voir la première pierre d’un projet en marche, je ressentais l’étrangeté du contraste entre des personnes heureuses de pouvoir partager leur compétence dans un projet et leur inquiétude par rapport à la difficulté de la vie dans leur pays, qui se dévoilait en même temps que les langues se déliaient, dans une ville ou la bière est pratiquement moins chère que l’eau.
J’ai toujours été mal à l’aise par rapport à la notion de #tourisme, qui certes rapporte certainement de l’argent localement, mais aussi crée une sorte de barrière entre les visiteurs et les habitants. Certaines discussions m’ont malheureusement conforté dans cette impression...



Un nouveau moteur de recherche pour seenthis
Nous avons travaillé ces deux dernières semaines, avec @marcimat et @rastapopoulos, à la programmation d’un #moteur_de_recherche générique pour #SPIP, basé sur #Sphinx, et très adaptable à différents types de sites. En l’appliquant à #seenthis, on obtient un outil dont les caractéristiques sont assez intéressantes :
– opérateurs logiques (et, ou, non)
– recherche de mots parmi une liste
– #proximité
– des #facettes permettent par ailleurs d’affiner la recherche, en proposant des #hashtags et des @people liés aux mots demandés
– une facette de date permet de filtrer par année (2014, 2013, etc).
– enfin, on propose plusieurs tris (par pertinence, date, ou en mettant en tête de liste les messages les plus partagés)
Je vous laisse découvrir tout cela :
– le moteur lui-même : ▻http://seenthis.net/recherche
– la documentation : ►http://seenthis.net/fran%C3%A7ais/article/moteur-de-recherche
– le code d’#indexer, le plugin générique pour SPIP : ▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/indexer/trunk
– le code du plugin qui l’adapte à seenthis : ▻https://github.com/seenthis/seenthis_sphinx
Commentaires et relevés de bugs sont très bienvenus.

Super bonne nouvelle : j’ai vraiment un mal de chien à retrouver d’anciens articles archivés. Merci pour votre travail.
Je viens de tester, c’est de la balle!
La recherche est sur le message ou sur le fil ?
Ça peut être intéressant de chercher des messages qui contiennent une image ou une vidéo ou qui a reçu des commentaires (dans le cas où on cherche un de nos messages et que ce sont des infos qui se retiennent bien).
Sinon une recherche sur le fil entier pour des messages qu’on recherche sur un sujet, par exemple si on cherche sur poutine et ukraine, ça peut rapporter pas mal de sujets en plus (surtout que souvent les billets sont taggés a posteriori par les autres membres)
Rechercher des fils dans lesquels des membres de seenthis ont participé ?
Bon c’est des idées en l’air, je sais pas s’il y a un réel besoin pour ça ?
La colonne de droite « follow » elle se base sur la recherche / les résultats ? Ça me met des comptes que je suis déjà en tout cas
Edit : ha non ça permet d’affiner la recherche en spécifiant un auteur, mais si j’ai fais ma recherche avec déjà un auteur, ça va sortir aucun résultat

Pas compris. J’ai essayé les # et je ne sais pas si je dois affiner les recherches parce que je me suis retrouvée dans un flux sans queue ni tête...bigre ! Je crois que je suis complètement crevée !

Je n’ai fait que quelques essais de recherche. Sans problème. L’interface est super claire et les affinages très bien venus.
Mais surtout, je vois des comptages. Alors, je n’ai pas pu m’empêcher…
Sur une entrée vide, on compte tout. Du coup, ça fait une super façon d’entrer dans les stats…
On a des unités statistiques différentes :
– pour les années, apparemment, il s’agit des billets (messages initiaux). Si tu implémentes un dépliement hiérarchique par mois, outre que ça permet de préciser le filtre chronologique (surtout utile pour l’année en cours), ça permettrait d’avoir l’activité mensuelle.
– pour les comptes (follow) et les tags, il me semble qu’il s’agit de toute l’activité (billet, commentaire, étoile)
Là aussi, peut-être un niveau hiérarchique inférieur permettrait de ventiler entre ces 3 types d’activités (ce qui permettrait de préciser quand on cherche une réponse dans une discussion)
Du coup, les totaux n’ont pas de raison de coïncider. Si mon interprétation est bonne, il y a eu (et il subsiste après effacement des comptes) 120000 billets (ça change tout le temps…) et comme le numéro du dernier est autour de 260400, cela fait de l’ordre de 1,2 « activité complémentaire » (commentaire ou étoile) par billet.
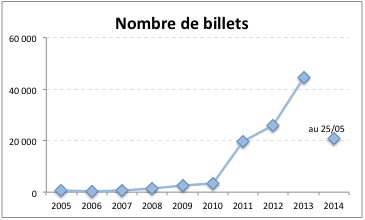
Juste pour voir, j’ai fait le suivi du nombre de billets par année.
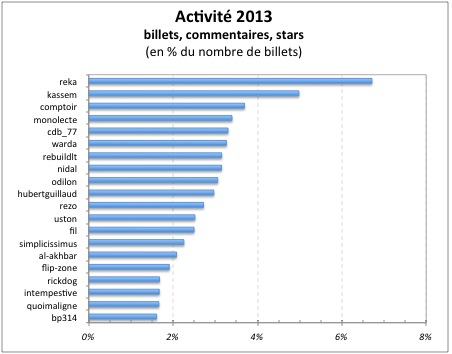
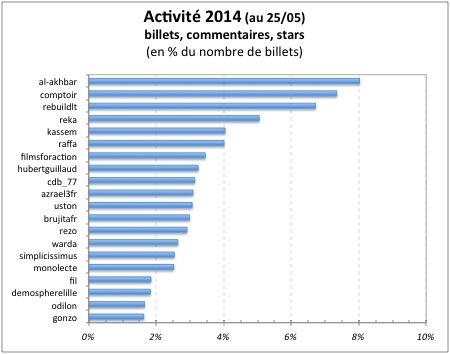
Et l’activité des top 20 (en % du nombre de billets)
(pour 2010, la somme des 20 follows fait 3548, alors que le nombre de billets est de 3520)
2013
2014
Éventuellement, un nouveau bloc par nombre « d’activité complémentaire » pour classer les billets par intensité de la discussion ou des étoiles (souhait qui a été exprimé, me semble-t-il).
Encore merci. Et bravo pour l’interface « naturelle » ou « invisible ».
Jolies déductions :)
La facette « follow » est établie sur la base de l’attribut multivalué {auteur initial + partageurs}. Les intervenants dans la discussion ne sont donc pas comptés en tant que tels (ils sont indexés dans un autre attribut, mais pas utilisés dans l’interface : l’idée est que si je ne partage pas un billet, mes suiveurs n’ont pas forcément vocation à être alertés que je suis en train d’y discuter).
Chacune des facettes, comme tu l’as constaté, est limitée aux 20 éléments ayant le plus fort effectif, et à condition qu’il soit > 1.
Le système recense à cet instant 156548 billets publiés. Il existe des billets effacés (11197 dont une trace reste dans le système, sans compter ceux de quelques tests, ou du compte machin, qui ont carrément été supprimés).
Pour ce qui est de fouiller plus avant dans les données, je pense qu’il sera plus efficace de créer des requêtes ad hoc. Le langage d’interrogation, très proche du SQL, est assez parlant.
Par exemple pour avoir le nombre de billets publiés mois par mois :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
La même chose pour les billets qui répondent à un critère fulltext :SELECT COUNT(*), YEARMONTH(date) as m FROM seenthis where MATCH('spip') AND properties.published=1 GROUP BY m ORDER BY m ASC LIMIT 1000;
etc.
Concernant la suggestion de trier selon l’intensité des discussions : il n’y aurait aucun obstacle technique, sachant que les éléments nécessaires (liste des participants à chaque discussion) sont déjà indexés. En revanche, il me semble qu’il s’agit d’une fausse bonne idée : j’ai comme un doute en effet sur l’intérêt de mettre en valeur des discussions qui impliqueraient de nombreuses personnes, mais qu’aucune ne souhaiterait partager…
La vocation du moteur de recherche est de permettre de trouver aussi rapidement que possible une information précise, les décisions doivent se baser uniquement là-dessus, pour cette page en tout cas. Mais l’outil permet d’imaginer d’autres « vues » sur les données, qui pourront servir à l’administration du serveur, à créer des pages annexes, à repérer des « corrélations » entre les sujets, des proximités entre auteurs, une analyse du « dictionnaire » global, et que sais-je encore. Tout un champ à explorer !
PS : la doc de SphinxQL : ▻http://sphinxsearch.com/docs/current.html#expressions
Tu sais que l’utilisateur est d’abord et avant tout pervers : il utilise les outils qu’on lui donne pour faire tout autre chose avec… Et, donc, oui je sais qu’il s’agit de recherche, pas de stats. Tavaikapa mettre des comptages.
Blague à part, en fait, je ne sais pas comment faire pour rentrer dans les tables de ST à des fins statistiques. À l’occasion (R ?), je jetterais bien un œil…

Oui @fil, pour la mise en avant des discussions « chaudes » (celles ayant le plus de participants et/ou celles ayant le plus de messages), je ne voyais pas ça spécialement dans la page de recherche. Mais dans une autre vue à part ce serait bien oui.
(Dans le même thème, un truc qui pourrait être bien, hors interface, ce serait aussi un flux Atom des commentaires postés par les gens qu’on suit.)
(une loi qui porte mon nom la classe .. ah mince c’est moi qui l’ai créée...)
Le menu pour affiner la recherche par facette semble avoir des bugs :
▻http://seenthis.net/recherche?recherche=%23permaculture+%40nicolasm+%23agriculture
– le tag agriculture n’est pas déjà coché dans le menu
– si je clique sur le tag alimentation ça me met cette url = ▻http://seenthis.net/recherche?recherche=%23agriculture&tag=%23alimentation (ça vire mon pseudo et le tag permaculture) alors que j’imaginais que ça rajoutais le tag alimentation en contrainte supplémentaire ? Même souci avec les facettes par auteur pour ▻http://seenthis.net/recherche?recherche=%23agriculture+

Ah, cool ! C’est possible d’obtenir les résultats sous forme de RSS ?

@homlett le moteur est accessible en RSS et en JSON :
▻http://seenthis.net/?page=sphinx.rss&recherche=sphinx
▻http://seenthis.net/?page=sphinx.json&recherche=sphinx
Attention c’est de la version alpha, je changerai probablement les URLs une fois que ce sera testé et stabilisé.
À noter les deux flux proposent des données complémentaires : uri, title, date, @login de l’auteur, tags et « snippet », c’est-à-dire l’extrait du contenu avec les mots repérés mis entre <b> (à styler comme tu veux, le gras rendant assez moche).
Ce qui manque je pense, à ce stade, c’est de pouvoir personnaliser (faire « mes messages » ou « messages de mon réseau » plutôt que « Tous les messages »).
En fait, j’ai beaucoup utilisé le moteur hier pour écrire mon dernier papier et je suis ravie de la facilité avec laquelle j’ai pu retrouver toutes les sources dont j’avais besoin. Souvent, j’associe deux termes pour mieux cibler ma recherche, et sans avoir besoin de me prendre la tête avec les opérateurs booléens, j’exhume très rapidement ce que je mettais des heures à chercher jusque là (et que je ne retrouvais généralement pas !). J’aime beaucoup le surlignage des termes recherchés et la possibilité de trier les résultats par date ou pertinence, de limiter par année, auteur, me ravit littéralement.
Je n’ai pas eu de bugs, pas de problème et mes requêtes ont toutes abouti.
Donc désolée de ne pas aider plus que cela, mais je suis juste la ravie de la crèche qui pensait depuis un bon moment que le gros défaut de Seenthis, c’était de ne jamais rien y retrouver !

@fil OK, c’est noté. Merci en tout cas, c’est top et ça manquait vraiment ! Par contre c’est vrai que <b> c’est moyen. Pourquoi pas un <span> ou même <em> ? Mais c’est pas très important.
En tout cas ça va permettre de faire de la veille sur #seenthis, @seenthis et seenthis ! ;-) ( ▻http://seenthis.net/messages/256466 )
Peut-être puis-je émettre un bidule qui serait bien pratique mais je ne sais pas si c’est le sujet de cette discussion. Serait-il imaginable de mettre une étoile à côté d’une réponse. Car parfois, il y a des réponses qui mériteraient d’être mentionnées dans les recherches. Voir des possibilités d’y répondre....
je ne vois pas le lien entre étoile et réponse de recherche ?
en effet c’est hors-sujet :)
pour gérer le développement de seenthis, on vient tout juste de mettre en place un compte github où vous pouvez envoyer des issues (problèmes ou demandes de fonctionnalités) et des pull-requests (des modifications du code source).
►https://github.com/seenthis

Est-ce qu’une migration vers SPIP 3 est prévue ?

Une petite amélioration du moteur : la recherche se fait désormais à partir de la racine des mots (lemmatisation) ; ainsi le moteur trouvera les messages contenant aussi bien le pluriel que le singulier, ou bien diverses formes des verbes conjugués (c’est censé fonctionner pour l’anglais et pour le français).
Si, à l’occasion, vous souhaitez rechercher la forme exacte d’un mot, utilisez l’opérateur = ; par exemple, une recherche de =terres évitera les messages contenant le mot terre au singulier seulement.
(Et pour répondre à @nhoizey : il me semble probable que les plugins seenthis fonctionnent déjà pour la plupart avec SPIP 3, je n’ai pas essayé mais je ne vois pas ce qui pourrait bloquer. Si dans tes tests tu vois des bugs, n’hésite pas à les signaler ou à envoyer une pull-request sur ►https://github.com/seenthis )


Bonjour
On m’a dit de m’adresser ici si je ne comprenais pas quelque chose.
Comme par exemple : comment faire pour afficher sur sa page personnelle un billet d’un autre utilisateur ? Il faut le mettre en favori, c’est tout ?
Je n’ai pas trouvé le bookmarklet en page d’accueil qui, paraît-il (dixit la page « le minimum à savoir »), transforme complètement le confort d’utilisation.
Merci d’avance !

Bonjour @bruno2, bienvenue !
Oui, c’est ça, pour afficher sur sa page le billet d’un autre, il suffit de le mettre en favori. C’est une fonction « repartage ».
Pour le bookmarklet, il est sur la page d’accueil ►http://seenthis.net, dans la colonne de droite, juste après À lire.
Autre question, tant que j’y suis :
Y aurait-il quelque part un badge seenthis que je pourrais coller sur mes sites perso pour guider mes visiteurs vers ma page ?
Non, on se le fabrique soi-même... #DIY
Bon, OK.
Autre question :
Pour suivre un thème, je n’ai pas trouvé d’autre moyen qu’utiliser le moteur de recherche, chercher le thème avec le # dans la page et cliquer dessus, puis ensuite faire « suivre le thème ».
Il n’y a pas moyen de faire plus simple ?
Fondamentalement plus simple, je vois pas comment. Mais il y a un lien « thèmes » dans le bandeau du haut, vers ►http://seenthis.net/tags avec la liste des thèmes/tags suivis.
Tu peux aussi directement taper l’url http://seenthis.net/tag/THEME_EN_QUESTION
À savoir : si par exemple tu suis le thème #seenthis, tu suis avec ses sous-thèmes : #seenthis_doc, #seenthis_todo, etc. Mais bien sûr, pas l’inverse.
Autre chose : devant chaque liens partagés, il y a un triangle. S’il est blanc, l’url n’a été partagée qu’une fois. S’il est noir, l’url a été partagée plusieurs fois. Et un clic sur le triangle renvoi vers la liste de tous les posts où elle apparait.
Last but not least, la mise en forme :
– du gras en encadrant avec le signe *
– de l’italique avec le signe _
– du code avec le signe `
– des citations avec Shift+Tab
Quand tu es connecté, tu ne vois que ceux auxquels tu es abonné. Sinon, tu vois les posts de tout le monde.
Pour voir les postes de tout le monde quand tu es connecté, c’est ►http://seenthis.net/all
Sauf que cette page « all » n’est liée nulle part, et que donc personne ne peut la deviner, nouveau ou pas (moi-même je ne m’en souvenais plus).

Bonjour et #merci,
J’utilise la recherche avec recherche ?annee=2016&order=stars
J’aimerais pouvoir ajouter quelque chose comme &moisdelannee=2
Y-a-t-il une syntaxe adaptée à ce désir ?
Pour le moment non, et je me demande si ça ne serait pas plutôt quelque chose comme date=2016-02 qu’il faudrait faire. À discuter sur ►https://github.com/seenthis/seenthis_squelettes/issues ?


Les projets git pour SPIP
▻http://git.spip.org/gitphp
▻https://twitter.com/webelys/status/469494198459457537
Merci @azerttyu ;-)

Oui c’est un scandale, le contributeur principal ne respecte pas les règles de commit :
–* ▻http://zone.spip.org/trac/spip-zone/browser/_plugins_/crayons
Il faut à minima un #trunk pour avoir du #git
On peut supposer que c’est lié à l’utilisation de l’outil de migration #git-svn qui peut faire des choses très sympa en récupération de l’historique avec l’une des options ’’’—stdlayout’’’ ou ’’’-T’’’ mais bon, ça peut être aussi autre chose, je fais que supposer... c’est souvent long à procéder, et le résultat n’est pas toujours à la hauteur, surtout quand les dev n’ont pas utilisé svn « comme il faut » pour gérer tags et branches ...
ô toi qui aime l’anglais, lis donc ça : ▻https://www.kernel.org/pub/software/scm/git/docs/git-svn.html

Yop
@fil tout #VCS recommande à minima la logique trunk/branches/tags, certains plugins suivent cette recommandation, d’autres non.
Il est parfois bon d’être rationnel et si possible de suivre les bonnes pratiques.
Autre point où copierons nous la branches créée depuis git dans la version svn ?
@james #git-svn n’est pas utilisé car ne fait pas le boulot voulu. Le « layout » utilisé permet d’être bijectif :
on peut contribuer indifféremment sur la copie git ou svn c’est pareil.
Question piège : à quoi ressemblerait le « layout » pour les plugins core ? :)
Est ce qu’on doit vraiment en passer par là, je dirais oui car il nous faut être cohérent pour ne pas se mettre des traverses dans les pieds, on a assez de bâtons pour le moment.
Je regarde pour que ce soit le plus transparent possible même pour ces plugins, mais ce n’est pas trivial.


Tiens, @xporte devient redac’chef de Rue89.
Ajout 19h44 :
Xavier de La Porte, nouveau rédacteur en chef de Rue89 - Le nouvel Observateur
▻http://rue89.nouvelobs.com/2014/05/22/xavier-porte-nouveau-redacteur-chef-rue89-252378
Syncthing - Un clone de BTSync pour se débarrasser de Dropbox
▻http://korben.info/syncthing.html
Syncthing – Un clone de BTSync pour se débarrasser de Dropbox
Je vous ai déjà parlé à plusieurs reprises de BTSync, le logiciel de synchronisation P2P initié par Bittorrent. Il est top, mais y’a 2 trucs qui me gênent avec cet outil :
1/ Il suffit d’entrer une clé pour que ça se synchro. Pas de mot de passe, pas d’approbation de l’ajout...etc. Du coup, même si le risque est limité, n’importe qui peut « deviner » ou voler votre clé et se synchroniser avec vous.
2/ Les sources ne sont pas ouvertes.
Et c’est là qu’entre en scène Syncthing.
Ah ! :) Voilà une très bonne nouvelle !
#BitTorrent #Chiffrement #Dropbox #Open_source #P2P #Synchronisation_de_fichiers


hubiC de OVH fait aussi très bien l’affaire !

@omikse Oui, j’utilise aussi hubiC, mais ça n’a pas grand chose à voir... BTSync (et Syncthing) permettent de maintenir synchronisées des données sans les confier à un tiers. J’ai une instance BTSync sur un Raspberry Pi et sur chacune de mes machines : c’est très pratique et très efficace.
Par ailleurs, j’ai aussi un compte hubiC où j’archive des données (après les avoir chiffré moi même bien entendu). hubiC me permet de mettre mes données à l’abri d’une défaillance technique, vol, incendie, etc.
Donc deux outils, pour deux usages complémentaires.
c’est un peu roots mais ça me dirait bien d’essayer ; l’installation (façon de parler) est très facile : on télécharge le truc et on l’ouvre…
mon node ID pour tester :CFZORZ CSQT7W CDUIKC KSKMMS NRQELS 3FLJKY IQIXD7 2BP5NB MC2A
installé sur un serveur sans interface graphique, pour piloter les réglages via l’interface web il faut ouvrir un tunnel ssh :
ssh -f fil@rezo.net -L 8082:127.0.0.1:39967 -N
l’interface de gestion est alors en local sur le port 8082 (39967 est le port qu’il a pris au lancement sur le serveur).
@fil OK, j’me lance aussi. J’essaie encore de comprendre la logique du truc... J’ai ajouté ton node. Voilà l’ID du miens :H6D5OP C3PUD7 77MQX6 BAQT3F 3JVJPU OVJZMT HVHVKF 64WERO 4CSA
Et merci pour l’astuce du tunnel.
J’ai ajouté « test1 », j’ai mappé le port 22000 sur mon modem-routeur vers mon serveur, j’ai ajouté rezo.net:22000 dans les Adresses dans la configuration de ton node, j’ai redémarré... rien y fait, tu es irrémédiablement : Disconnected
un petit log :
22:37:07: Connection to homlett closed: remote has extra repository "test_homlett"
22:37:07: Index from homlett for nonexistant repo "test_homlett"; dropping
22:37:07: Connection to homlett closed: flate: read error at offset 268: read tcp xx.xx.xx.xxx:22000: use of closed network connection
Je suis repassé sur dynamic, c’est juste que j’étais à ta recherche !
Pour info et pour les autres : ça marche !
Si je peux jouer avec vous ;-)
OGWDFT LCOA5D Y5AHQE BWHBIF VTDH4I 5AMMUD 3N3Y6H 4RRGH6 V5MA
Syncthing replaces Dropbox and BitTorrent Sync with something open, trustworthy and decentralized. Your data is your data alone and you deserve to choose where it is stored, if it is shared with some third party and how it’s transmitted over the Internet.
Using syncthing, that control is returned to you.
Pour plus d’infos : ►http://seenthis.net/messages/257227
Kickstarter : l’édition transformée par le financement participatif
▻http://www.actualitte.com/international/kickstarter-l-edition-transformee-par-le-financement-participatif-50242.
Ces chiffres démontrent bien que le crowdfunding a rencontré son public aux Etats-Unis pour ce qui est du milieu de l’édition. Et la bande dessinée, que Kickstarter présente comme une catégorie à part, représente à elle seule, 1401 projets lancés et 12,5 M $ de promesses de dons en 2013. L’année précédente, il y avait 1 170 bandes dessinées projets lancés et 9.2 millions de dollars de promesses de dons.
Sur Kickstarter, les projets BD ont un taux de près de 50 % de réussite. Cela place ce secteur au quatrième rang concernant le pourcentage de réussite, derrière la danse (70 %), le théâtre (64 %) et la musique (55 %).
Documentaire lui même financé sur ulule
"Sous les bulles, l’autre visage de la Bande Dessinée" est un documentaire de 60 minutes, réalisé par Maiana Bidegain.
Il s’agit d’une enquête inédite dans l’univers de la Bande Dessinée franco-belge pour en découvrir la réalité économique contrastée, à travers ses différents acteurs. Entre « success stories » et angoisses face à un secteur en pleine mutation, face à la concurrence des comics et surtout des mangas, un monde se révèle, beaucoup plus féroce et fragile que l’on aurait pu l’imaginer.
Shinkansen japonais contre TGV français - La claque - UFC Que Choisir
▻http://www.quechoisir.org/transport/train-route/actualite-shinkansen-japonais-contre-tgv-francais-la-claque
En France, la SNCF n’a jamais trouvé de formule satisfaisante pour son wagon-restaurant. Lourdement déficitaire, il tire les prix des billets vers le haut, dans la mesure où il prend la place d’une cinquantaine de sièges, au bas mot. Que vous vous résigniez ou non à faire la queue pour un sandwich dans un TGV, vous payez le restaurant en achetant un billet…
J’ai eu l’occasion de prendre un ICE... billet intermodale avion/train qui m’amène de ma ville de départ en France à ma ville d’arrivée en Allemagne. Rien que ça, c’est génial. Pas de barrières de contrôle/compostage entre les différents moyens de transport : les accès sont ouverts, le flux des voyageurs ne s’écrase jamais contre un barrage mais s’écoule en douceur. Tu sors de l’avion et tu es super surpris de te retrouver d’un coup face à ton train. À Lyon Saint-Ex, pour soit-disant gare intermodale, tu ne passes pas d’un transport à l’autre par hasard. Il y a de l’espace dans les wagons, tu n’as pas l’impression d’être tassé... je garde de cette expérience une belle impression de fluidité, de facilité du trajet, alors que sur le réseau français, c’est toujours queue, bousculades, cavalcades dans des couloirs étriqués, contrôles et espace restreint.
Camille Lepage avait-elle sa carte de #presse de la CCIJP ?
▻http://www.grincant.com/2014/05/14/camille-lepage-avait-elle-sa-carte-de-presse-de-la-ccijp
Elle était en « freelance ».
C’est-à-dire à son compte.
Devant tout financer par elle-même.
Son matériel.
Son voyage, sa vie là-bas.
La promotion de son travail.
De belles photos qui pouvaient rester invendues.
Ou achetées une bouchée de pain, sous forme de droits d’auteur.
En attendant une utopique célébrité.
Ils sont maintenant fiers de dire qu’elle a été maintes fois publiée.
New York times, NYT Lens Blog, Time Lightbox, Le Monde, Der Spielgel, Libération, Le Nouvel Observateur, La Croix, The Sunday Times The Guardian, BBC, Wall Street Journal, Washington Post, Le Monde, Vice Magazine, Al Jazeera.
Mais pourquoi était-elle freelance alors ?
L’avenir de ces jeunes qui aiment leur métier, qui veulent changer le monde.
C’est maintenant de travailler sans moyens, puis d’espérer.
Espérer pouvoir retirer de leur travail quelques fifrelins.
Les grands groupes dits de presse, les chaînes d’info, les agences…
Ne commandent plus, n’engagent plus, n’accompagnent plus.
Non, il faut tout leur amener sur un plateau avant qu’ils n’envisagent d’acheter.

Intéressant, pour une discussion et un débat dans un futur moins chargé (là pas trop le temps) mais questions fondamentales :
Les grands groupes dits de presse, les chaînes d’info, les agences… Ne commandent plus, n’engagent plus, n’accompagnent plus. Non, il faut tout leur amener sur un plateau avant qu’ils n’envisagent d’acheter.
Quand à cette question :
Mais pourquoi était-elle freelance alors ?
J’ai lu à plusieurs reprise, mais je n sais pas si c’est vrai, qu’elle a dit elle même que sa seule vision du journalisme, c’était d’être complètement indépendant(e). Mais même en free-lance, on n’est pas nécessairement plus libre ou plus indépendant, (même si je pense que c’est mieux) que lorsqu’on est salarié d’un grand groupe de presse, à moins de renoncer au confort et à la sécurité :) ce qui avait l’air d’être le cas pour elle.
A moins vraiment d’une structure et/ou d’un contexte « particulièrement » respectueux, éthique et visionnaire, mon impression est qu’aujourd’hui, pour faire un journalisme digne de ce nom, c’est beaucoup mieux d’âtre dans le monde du dehors, même si c’est moins confortable.
Voilà aussi d’autres questions intéressantes dont il faudrait débattre ici : journalisme du futur, indépendance, liberté d’expression dans les journaux, politique des grands groupes de presse.

Hommage d’un étudiant malien à Camille Lepage
▻http://rue89.nouvelobs.com/2014/05/15/hommage-dun-etudiant-malien-a-camille-lepage-252192
Mais l’énergie que tu avais déployée, l’humanité et le professionnalisme dont tu avais fait preuve m’ont marqué et me marqueront à jamais.Tandis que je traversais de graves difficultés, et bien que tu ne connaissais rien de plus de moi qu’une photographie et quelques informations éparses, tu avais eu un geste sublime. Tout simplement, sans poser de conditions tu m’avais tendu la main, à ta manière.
Faites passer le coup de colère de Wilfried Estève contre le site web d’un « news magazine », très franco-centré, qui crédite les photos de Camille Lepage avec la mention « copie d’écran ».....
Wilfrid Estève #coupdegueule Je viens de découvrir le « folio » qu’à fait le magazine Le Point.fr en hommage Camille, il est composé que de captures d’écrans et les photographies ne sont plus créditées à son nom.
Au-delà du fait que c’est illégal, ce genre de pratique est honteuse de la part d’un média ! Comment le directeur de la rédaction et les journalistes peuvent-ils permettre cela ?
Je tiens à préciser que les droits de l’ensemble des publications qui sont gérées par le studio hans lucas iront intégralement à la famille et que, jusqu’à présent, toutes les rédaction ont eu une attitude irréprochable.
Le magazine Le Point touche des aides de la presse et les membres de la rédactions ont une carte de presse. Comment déontologiquement, ils peuvent laisser passer ceci !?!
Nous allons les contacter pour avoir des explications.
Les photographies ne sont plus créditées Camille Lepage mais :
6Medias © Capture d’écran Facebook
6Medias © Capture d’écran Instagram
▻http://www.lepoint.fr/medias/en-images-hommage-a-camille-lepage-14-05-2014-1822859_260.php

« Défendre nos villes contre les ravages du techno-capitalisme »
►http://www.lemonde.fr/technologies/article/2014/05/01/defendre-nos-villes-contre-les-ravages-du-techno-capitalisme_4410220_651865.
Pourquoi avez-vous commencé à protester ?
Etre témoin des expulsions de locataires à San Francisco, assister à la prolifération des technologies de surveillance, voir de nos yeux la dévastation de l’environnement a suffi à nous pousser à agir. Nous ne pouvions plus rester assis et regarder cette dynamique d’exploitation et d’avarice s’étendre sans rien faire.

La radicalisation des « anti-high-tech » bouscule San Francisco
►http://www.lemonde.fr/technologies/article/2014/05/01/pourquoi-les-manifestations-anti-high-tech-se-radicalisent-a-san-francisco_4

dans l’article signalé par @parpaing je relève
La radicalisation des « anti-high-tech » bouscule San Francisco
►http://www.lemonde.fr/technologies/article/2014/05/01/pourquoi-les-manifestations-anti-high-tech-se-radicalisent-a-san-francisco_4
[les manifestants se dirigent vers] la maison de Kevin Rose, une figure de la Silicon Valley. Fondateur de l’agrégateur d’actualités Digg, il est désormais associé chez Google Ventures, le fonds de capital-risque du moteur de recherche.
Sous ses fenêtres, les protestataires déploient des banderoles. « Parasite ! », est-il écrit sur l’une d’entre elles. Ils distribuent des tracts à ses voisins, dénonçant le rôle de M. Rose dans la « destruction de San Francisco », en finançant des start-up qui attirent « des nouvelles vagues de “techies” qui gagnent quatre fois plus que les travailleurs ».
L’intéressé, également visé par un site le décrivant comme « une personne horrible », est sorti dans la rue pour en discuter avec eux, dans une ambiance tendue, comme le montre la vidéo ci-dessous.
et que dit Rose à ce moment ? : "Vous filmez ? arrêtez de filmer et on pourra parler".
« La municipalité est capable d’inventer des exonérations fiscales pour ceux qui gagnent des milliards », s’indigne Margaret, 64 ans. « Mais dans l’hôpital où je travaille, on me dit qu’il n’y a pas d’argent public pour financer nos rénovations et nos projets. »

C’est en effet un passage de la vidéo proprement ahurissant. D’une certaine façon, il a bien raison de demander à ce que la caméra s’arrête. Pas idéal pour engager un débat. Et dans le même temps, il est l’homme de Google, l’homme de YouTube d’une certaine façon. Il y a là toute la contradiction de notre monde. Quelle scène.
sans oublier #google_glass et ses « explorateurs » qui chouinent quand ils se font interpeller parce qu’ils filment tout

Je me souviens des actions d’un groupe anti-vidéosurveillance avec de vrais caméras en train de suivre les gens dans la rue à Levallois aux carrefours vidéosurveillés. Ils se faisaient insulter évidemment, jusqu’à devoir montrer qu’il n’y avait pas de cassette et que leurs caméras n’avaient rien filmé, ça créait toujours un certain choc quand les passants réalisaient à contrario qu’ils supportaient celles de la police sans broncher !
Carte des drones
Vous cherchez où voler avec votre #drone en respectant la législation française ? ►http://www.aip-drones.fr/carte/aip-drones … est fait pour vous !
via @rodoq ►https://twitter.com/rodoq/status/466493526667436032
Automattic lève 160 millions de dollars : un tournant pour WordPress
▻http://www.linformaticien.com/actualites/id/33041/automattic-leve-160-millions-de-dollars-un-tournant-pour-wordpress.a
Avec un vocabulaire du journaliste et de l’interviewé assez combattif ;)
#stratégie #marché #concurrentiel #gagner #croissance #dominante #imposer #parts_de-marchés #conquérir

Vous trouvez que votre porte de garage est un peu fade ? //
▻http://photosilke.blogspot.fr/2013/03/fwd-puglisi-someone-is-making-few-bucks.html?m=1
une critique ici :
La “vraie vie” sent un peu le camembert | L’Atelier des icônes
▻http://culturevisuelle.org/icones/3000
Le problème, c’est que la « vraie vie » déconnexionniste ressemble comme deux gouttes d’eau à une pub pour camembert industriel, c’est à dire au cliché marketing de la vie rurale selon le rite mormon. Dans le rêve déconnexionniste, personne n’est jamais coincé dans le métro aux heures de pointe, ni humilié par son chef de service, ni infantilisé par le représentant d’un service administratif, ni harcelé par de gros lourds, etc… Tout n’est que luxe, calme et jeux d’enfants – deux jeunes gens, évidemment beaux et hétérosexuels, qui échangent un regard finiront mariés et propriétaires d’une maison en banlieue (et non pas divorcés et surendettés).

Hier je partageais ma frustration de photographe amateur parce que prendre des photos, quand on est en famille, c’est à coup sûr imposer à la petite famille de nous attendre tous les 100 mètres... quand on est en randonnée en particulier. Et pour la relève des mails, des notifications FB, et tout et tout, ça crée c’est certain un fossé avec les proches. Et j’estime donc qu’une partie du message est valide. Mais... oui, les stéréotypes dénoncés par André G. sont tout à fait saoulant (excluant) et réduisent la portée du message. On avait d’ailleurs des critiques approchantes à l’égard de cette vidéo tout à fait percutante d’inversion des genres, qui du fait de l’utilisation de stéréotypes racistes réduisait drastiquement sa portée (cf. ►http://seenthis.net/messages/224511)
Le podcast de @xporte entendu ce matin
▻http://rf.proxycast.org/889477367808925696/13454-07.05.2014-ITEMA_20624685-0.mp3
« Look up » ou comment les internautes déclarent leur bonne santé - Information - France Culture
▻http://www.franceculture.fr/emission-ce-qui-nous-arrive-sur-la-toile-ce-qui-nous-arrive-sur-la-toi
Mais le problème n’est pas la là, le problème ce n’est pas le régime de vérité du discours ; le problème c’est : pourquoi les gens approuvent-ils ce propos qui ne correspond pas à leur expérience ? Et y répondre permettrait de résoudre ce paradoxe assez drôle qui veut que cette vidéo bénéficie à plein de pratiques communicationnelles – en particulier les réseaux sociaux – qu’elle critique violemment, c’est-à-dire que les gens qui la partagent, qui la commentent de « Wahoo ! Amazing. You absolutly have to watch this » se livrent exactement à ce que dénonce la vidéo. Et on peut rationnellement supposer qu’ils se déconnecteront pas définitivement après ce dernier commentaire.
Si on consière seenthis comme un réseau social, ma réponse est que je l’ai partagé, non pas parce que j’adhère/j’aprouve complètement à l’idée, mais plutôt parce que ça nous rappelle (en exagérant bien le trait) que le virtuel est bien (trop parfoit) virtuel.
Et voilà aussi le point de vue de Thierry Crouzet :
Quand on ne veut pas comprendre la déconnexion… parce qu’on vit de la connexion
►http://blog.tcrouzet.com/2014/05/12/quand-on-ne-veut-pas-comprendre-la-deconnexion-parce-quon-vit-de-la-c
La déconnexion implique une autre connexion avec le Net, les arbres, les étoiles… Je peux bien être connecté et déconnecté en même temps, par exemple des sites d’actualités. Il n’existe pas une seule connexion, une seule manière de vivre le numérique. La déconnexion s’impose quand une norme s’impose à nous. Le succès de Turk n’est que le symptôme d’un ras-le-bol.
Kik Messenger | Fast, Simple, Personal Smartphone Messaging
▻http://kik.com
Kik is the first smartphone messenger with a built-in browser. You can talk, browse and share with your friends. What’s not to love?
visiblement les jeunes utilisent ça (actuellement)
Inside the High-Stakes Battle to Control How You Talk to Friends | Business | WIRED
▻http://www.wired.com/2014/02/ff_messagingwars/?cid=co19099634
In less than two years, services like WhatsApp, Snapchat, Kik, Line, KakaoTalk, and WeChat have grown from nothing to become social lifelines for millions of users.
Panopticlick
►https://panopticlick.eff.org
Is your browser configuration rare or unique? If so, web sites may be able to track you, even if you limit or disable cookies.
Résultat pour moi :
Your browser fingerprint appears to be unique among the 4,103,324 tested so far.
Currently, we estimate that your browser has a fingerprint that conveys at least 21.97 bits of identifying information.
Sur linuxfr, quelqu’un redirige vers Tor Browser :
►https://www.torproject.org/projects/torbrowser.html.en
#tor #anonymat

Your browser fingerprint appears to be unique among the 4,103,438 tested so far.
Currently, we estimate that your browser has a fingerprint that conveys at least 21.97 bits of identifying information.
Ça parait donc tout à fait standard : )
We identified only three groups of browser with comparatively good resistance to fingerprinting: those that block JavaScript, those that use TorButton, and certain types of smartphone. It is possible that other such categories exist in our data. Cloned machines behind rewalls are fairly resistant to our algorithm, but would not be resistant to fingerprints that measure clock skew or other hardware characteristics.
Idem.
Vu tout ce qu’il teste (tous les plug-ins avec leurs numéros de version et de sous-version), c’est un peu normal. Avec ça, il n’y aurait que 2 machines ayant la même configuration que moi parmi les 4M testées.
En ne prenant que ma config (MacOS, Safari, etc.), ça monterait à 56 machines.
Testé sur un portable PC, ma config (plug-ins) est unique, mon user-agent (hors plug-ins), beaucoup moins : un peu moins de 1200 machines similaires.
Impressionnant ! il suffit donc d’avoir un site attractif et d’enregistrer tout le monde… Ou plusieurs en variant les domaines d’intérêt.
In this sample of privacy-conscious users, 83.6% of the browsers seen had an instantaneously unique fingerprint, and a further 5.3% had an anonymity
set of size 2. Among visiting browsers that had either Adobe Flash or a Java Virtual Machine enabled, 94.2% exhibited instantaneously unique fingerprints and a further 4.8% had fingerprints that were seen exactly twice. Only 1.0% of browsers with Flash or Java had anonymity sets larger than two.
Encore plus impressionnant : le changement rapide de ces infos identifiantes (succession des versions) n’empêche pas l’identifiabilité
Unfortunately, we found that a simple algorithm was able to guess and follow many of these fingerprints changes. If asked about all newly appearing fingerprints in the dataset, the algorithm was able to correctly pick a “progenitor” fingerprint in 99.1% of cases, with a false positive rate of only 0.87%.
Ah la vache, les polices de caractères du système semblent un élément déterminant du fingerprinting... Si t’aime la typographie... beware !
Chez moi, j’ai :
Your browser fingerprint appears to be unique among the 4,104,460 tested so far.
Currently, we estimate that your browser has a fingerprint that conveys at least 21.97 bits of identifying information.
3000 tests par jour
Your browser fingerprint appears to be unique among the 4,107,333 tested so far.
Currently, we estimate that your browser has a fingerprint that conveys at least 21.97 bits of identifying information.
▻https://panopticlick.eff.org/faq.php
How many people are unique ?
About 85% and falling, as the dataset gets large
même avec #tor_browser je suis assez bien fliqué… mais visiblement c’est la variable ci-dessous qui m’identifie le plus, or elle change dès qu’on resize le navigateur :
Screen Size and Color Depth 22.29+ bits
Mysearch version 1.0 et paquet #debian | Tuxicoman
▻http://tuxicoman.jesuislibre.net/2014/05/mysearch-version-1-0-et-paquet-debian.html
Ça fait un petit moment que je travaille sur mon projet de #moteur_de_recherche anonymisé. Je l’utilise depuis quelques mois et il est maintenant prêt à entrer en production et découvrir le monde !
Je l’ai appelé Mysearch. Il s’agit d’une application qui va faire office de proxy entre vous et les grands moteurs de recherche du web.